Grounding : ce qu'une IA retient vraiment de votre page

Être bien positionné sur Google et être réellement lu par une IA sont devenus deux choses distinctes. Une page peut occuper la première place sur une requête et ne rien peser dans la réponse de ChatGPT, de Perplexity ou de l'AI Mode — non parce qu'elle est mal référencée, mais parce que l'IA, une fois qu'elle l'a trouvée, n'en retient que quelques phrases, et que ce ne sont pas toujours celles qui comptent.
Dans un article précédent, j'ai distingué les deux mécanismes derrière une réponse d'IA : une phase de récupération, déterministe et mesurable, qui sélectionne des passages dans un index, et une phase de génération, probabiliste, qui recompose la réponse à partir de ces passages. J'y notais un point sans m'y arrêter : l'IA ne retient pas des pages entières, mais des fragments. C'est précisément là que reprend cet article.
La question est celle du comment. Comment l'IA décide-t-elle quels passages — et, on va le voir, quelles phrases — elle retient de votre page ? Cette sélection n'a rien d'aléatoire : elle obéit à des mécaniques observables. Un budget de récupération limité, une extraction au niveau de la phrase, une nette préférence pour le début de page, une dépendance à la formulation exacte de la requête.
Comprendre ces mécaniques ne débouche pas sur une nouvelle checklist technique. Cela débouche sur une manière d'écrire : placer l'essentiel en tête, rédiger des passages qui se suffisent à eux-mêmes, rester factuel. Je vais d'abord détailler ce que l'IA fait concrètement de votre page, puis ce que cela change pour la façon dont vous la rédigez.
Résumé exécutif
- Une IA ne lit pas votre page entièrement : elle ancre sa réponse sur un budget limité — environ 2 000 mots pour Google —, réparti entre les sources selon leur rang. Au-delà d'une certaine longueur, allonger une page dilue sa couverture : la densité compte plus que le volume.
- La sélection est extractive et se fait phrase par phrase, avec une forte préférence pour le début de page. Une même page n'expose pas les mêmes phrases selon la requête, et chaque moteur — ChatGPT, Perplexity, Copilot — cherche à sa manière.
- La conséquence n'est pas une checklist technique mais une manière d'écrire : commencer par la réponse, des passages qui se tiennent seuls, des entités nommées, du factuel, une intention dominante par page.
- « Structurer » aide quand cette structure est celle d'une écriture claire ; ce n'est pas un levier technique en soi. Les faux leviers — miroirs Markdown, schema pour les citations — restent sans effet démontré.
- Deux conditions encadrent le tout : que votre page soit récupérable (un site lent ou qui bloque les robots IA est écarté d'emblée), et que l'IA cherche réellement sur le web — ce que la version gratuite fait bien moins que la payante.
Sommaire
- Récupérer n'est pas tout lire : le budget de grounding
- Comment l'IA choisit vos phrases : extraction phrase à phrase et biais d'ouverture
- Une même page, des lectures différentes : la requête décide
- Ce que ça change pour votre écriture — et où s'arrête le « levier »
- Avant tout ça : être récupérable
Récupérer n'est pas tout lire : le budget de grounding
Quand une IA ancre une réponse dans des sources — ce qu'on appelle le grounding —, elle ne charge pas votre page entière. Elle travaille avec un budget. Dan Petrovic l'a mesuré : sur 7 060 requêtes, le volume de contenu retenu pour ancrer une réponse de Google est plafonné à environ 2 000 mots par requête, quel que soit le nombre de sources ou la longueur des pages. L'enveloppe est fixe : on ne l'agrandit pas, on s'en partage les parts.
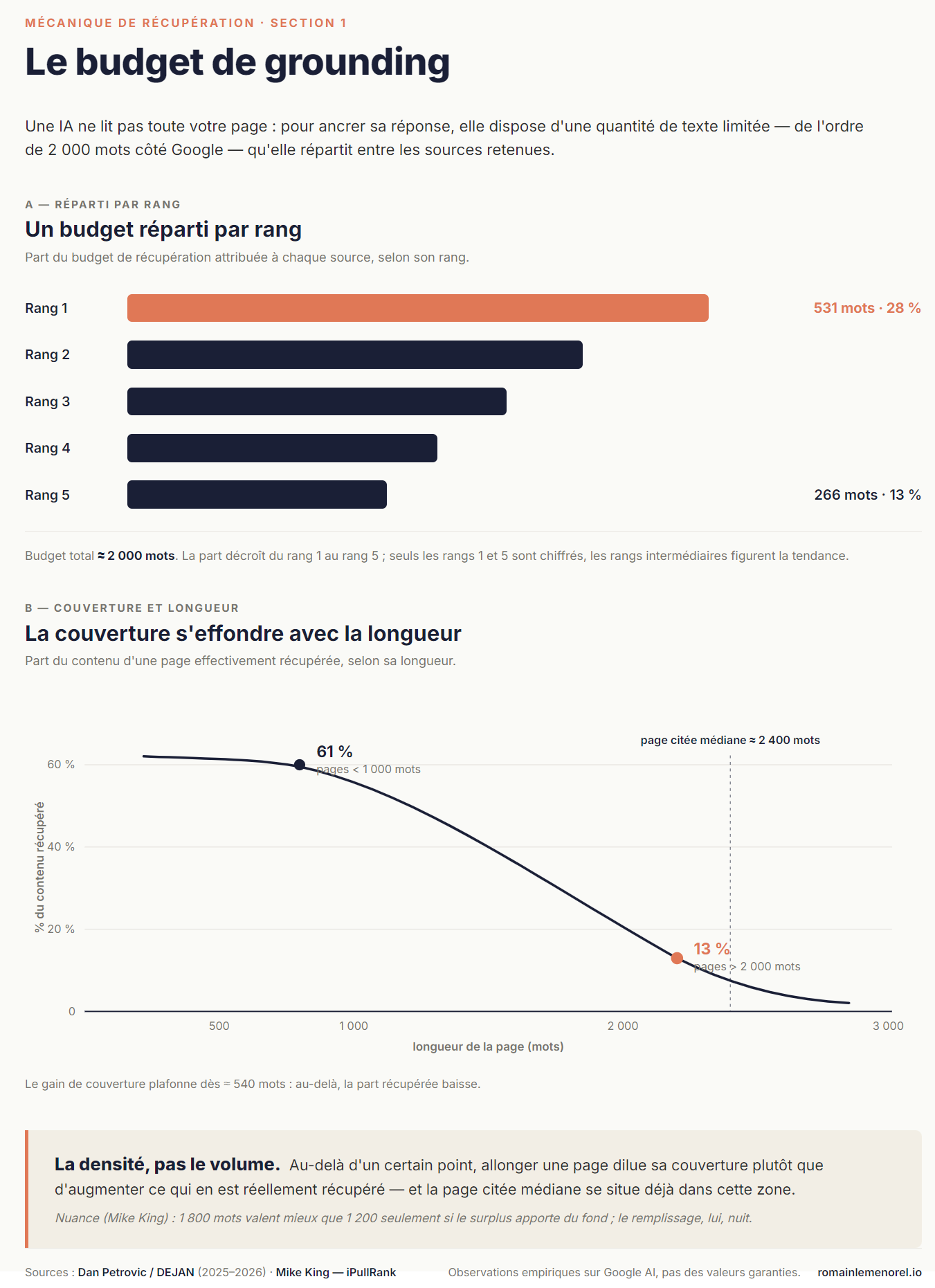
Cette enveloppe se répartit selon le rang. La source classée première reçoit environ 531 mots, la cinquième environ 266 — deux fois moins. La conséquence rejoint l'article précédent : le rang continue de décider, y compris à l'intérieur de l'AI search. Être bien positionné organiquement n'est pas un reste de l'ancien SEO ; c'est ce qui détermine votre part du budget de grounding.
Le second constat est moins intuitif. Au-delà d'une certaine longueur, une page plus longue n'obtient pas davantage de mots sélectionnés — elle voit seulement son taux de couverture chuter. Une page resserrée de 800 mots obtient plus de 50 % de couverture ; une page de 4 000 mots tombe à 13 %. La sélection plafonne autour de 540 mots : au-delà, vous diluez.
Petrovic le résume en une formule : la densité bat la longueur. La mise en perspective vaut d'être posée — la page web médiane fait environ 2 400 mots, c'est-à-dire que la plupart des pages ont déjà dépassé le point où s'allonger les sert. L'étude de Mike King va dans le même sens : les pages citées font en moyenne 1 800 mots contre 1 200 pour les non citées, mais ajouter des mots sans ajouter de matière — des entités, des faits — fait baisser la probabilité de citation. La longueur n'est pas le levier. La densité l'est.
Une précaution sur ces chiffres : ce sont des observations empiriques solides sur le grounding de Google, pas une loi démontrée — les 2 000 mots sont une médiane, et les facteurs concurrents comme l'autorité ou la fraîcheur ne sont pas isolés. Mais ils tiennent à la mi-2026, et ils pointent tous dans la même direction.
Reste à savoir non plus combien l'IA retient, mais comment elle choisit — quelles phrases de votre page deviennent sa matière. C'est l'objet de la section suivante.
Comment l'IA choisit vos phrases : extraction phrase à phrase et biais d'ouverture
On sait maintenant combien l'IA retient. Reste le plus important : comment elle choisit. Et là, une précision change la perspective. L'IA ne rédige pas un résumé de votre page — elle en extrait des phrases existantes, comme un surligneur. Elle ne reformule pas : elle sélectionne. Dan Petrovic l'a établi en inspectant les données brutes renvoyées par l'API de grounding de Gemini.
L'unité de sélection, c'est la phrase. Pas le paragraphe, pas le passage : la phrase. Le système découpe votre page en phrases, score chacune par rapport à la sous-requête traitée, et assemble les mieux notées — reliées par des points de suspension quand elles ne se suivent pas. Chaque sous-requête tire ainsi son propre jeu de phrases.
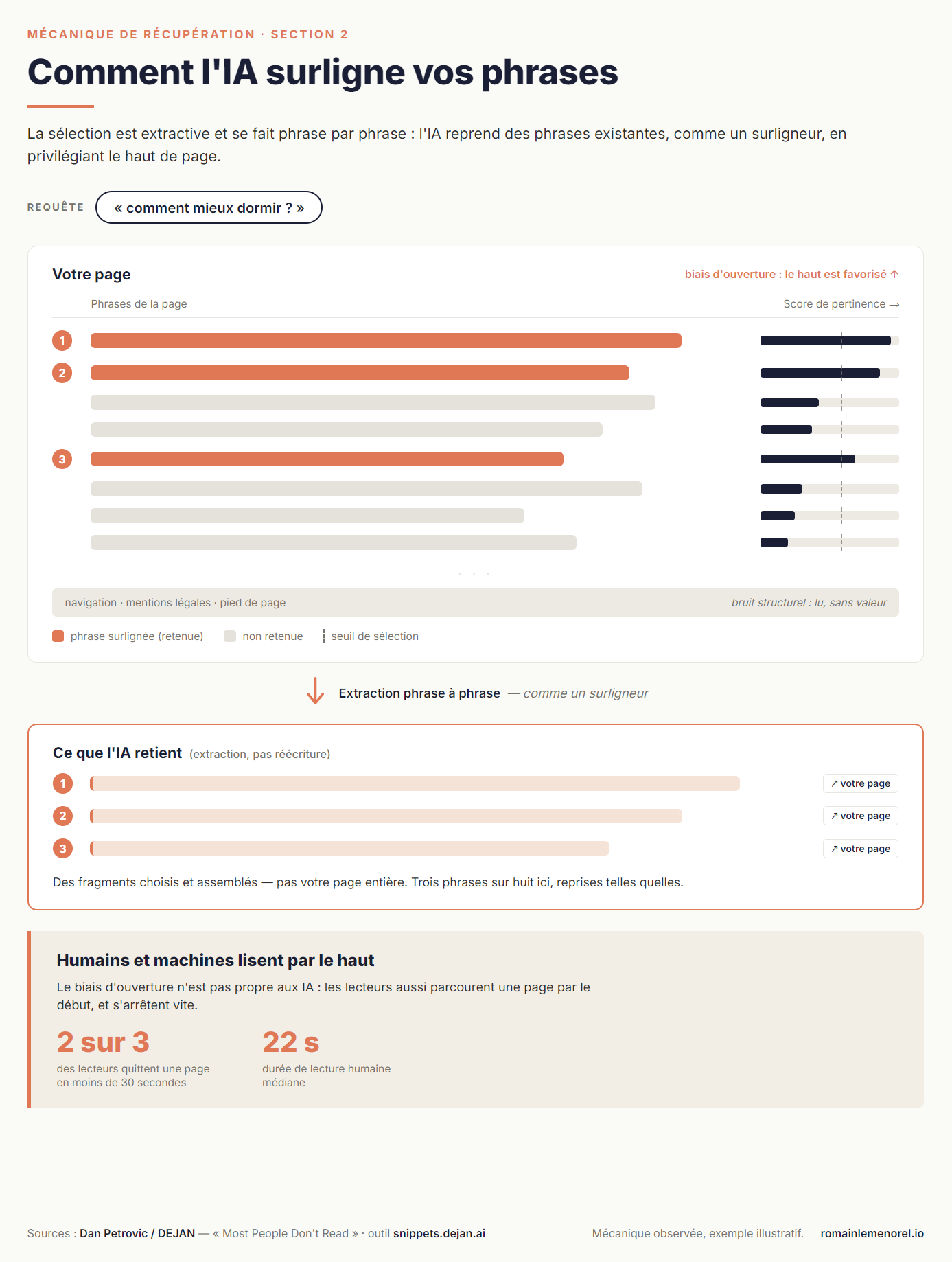
Premier biais, et il est marqué : les phrases d'ouverture sont prises presque en bloc, quel que soit leur contenu. Petrovic parle d'un fort biais de position. Concrètement, vos premières phrases pèsent davantage que les suivantes — non parce qu'elles sont meilleures, mais parce qu'elles sont en tête.
Second point, moins attendu : le bruit structurel n'est pas écarté. Titres, entrées de sommaire, artefacts de code sont traités comme des phrases et scorés avec le reste. Sur une page surchargée, des fragments sans contenu réel entrent dans la sélection au même titre que vos phrases utiles — et peuvent être retenus à leur place.
Ce biais d'ouverture n'a rien de propre aux machines — et c'est là que l'humain et la machine se rejoignent. Petrovic a mesuré par ailleurs le comportement de lecture humain sur une de ses pages : deux tiers des visiteurs partent en moins de trente secondes, la présence médiane est de vingt-deux secondes. Le premier paragraphe décide, côté humain comme côté machine : même point d'attention, le haut de la page. (Échantillon réduit, à prendre comme une illustration ; la convergence avec le biais de grounding, elle, est nette.)
Pour le voir concrètement, Petrovic a publié un outil — snippets.dejan.ai — qui montre, requête par requête, quelles phrases exactes Gemini extrait d'une page. C'est la matérialisation de l'écart entre être bien classé et être réellement repris.
Reste que ces phrases ne sont pas toujours les mêmes. Le système les score par rapport à la requête, ce qui veut dire qu'une même page n'expose pas les mêmes phrases selon ce qu'on lui demande. C'est l'objet de la section suivante.
Une même page, des lectures différentes : la requête décide
On vient de voir que le système score vos phrases par rapport à la requête. La conséquence est directe : une même page n'expose pas les mêmes phrases selon ce qu'on demande. Votre contenu n'est pas lu d'un bloc — il forme une carte sémantique, et chaque requête tombe sur une zone différente.
Petrovic l'a illustré sur un seul article — des tisanes et une maladie chronique — soumis à sept formulations de requête. Six d'entre elles, génériques, ne font remonter que la section « conseils généraux », environ 20 % du contenu. Une seule, la plus précise, fait remonter le cœur détaillé de l'article. La spécificité de la requête déverrouille les couches profondes de votre page : votre expertise la plus fine ne ressort que pour des questions assez précises pour aller la chercher. La polarité joue aussi — une requête « à éviter » fait apparaître des mises en garde que les requêtes positives manquent. (Démonstration sur un cas, à prendre comme telle ; l'effet, lui, est net.)
Vous l'avez vu dans l'article précédent : l'IA ne pose pas votre question telle quelle, elle la décompose en sous-requêtes. Ce qu'il faut ajouter ici, c'est leur forme. Petrovic a capturé plus de 360 000 de ces sous-requêtes réelles : 71 % font sept mots ou plus, et elles sont riches en entités. Vous n'êtes donc pas évalué sur le mot-clé court, mais sur des formulations longues et précises, souvent absentes des outils de recherche de mots-clés classiques.
Dernière variable, et elle est de taille : chaque moteur cherche à sa manière. Profound a comparé ChatGPT, Perplexity et Copilot sur 10 000 prompts. ChatGPT se comporte en chercheur — 91 % de ses requêtes de recherche sont uniques, il ne refait quasiment jamais la même recherche pour une même question. Perplexity reste proche d'un moteur classique : il réutilise ses requêtes et colle au mot-clé. Copilot, lui, compresse. Côté francophone, RESONEO confirme l'architecture interne de ChatGPT Search : un classifieur décide d'abord s'il faut chercher, puis le système lance plusieurs requêtes en parallèle — ChatGPT n'est pas un moteur unique, c'est un système orchestré.

La conséquence pratique : votre contenu doit rester trouvable quelle que soit la reformulation — d'autant plus pour ChatGPT, le plus mouvant des trois. Un format résiste mieux que les autres à travers les trois moteurs : « le meilleur [telle catégorie] ». C'est l'un des angles d'entrée les plus durables.
Budget, extraction, biais d'ouverture, dépendance à la requête, comportement par moteur : toutes ces mécaniques pointent vers une seule question pratique — comment écrire pour elles ? C'est l'objet de la section suivante.
Ce que ça change pour votre écriture — et où s'arrête le « levier »
Toutes ces mécaniques — budget, extraction phrase à phrase, biais d'ouverture, dépendance à la requête — se traduisent en une seule chose pratique : une manière d'écrire et non une liste de réglages techniques. Voici les gestes qui en découlent.
Commencer par la réponse. Le biais d'ouverture du grounding le commandait déjà ; les embeddings le confirment. Andrea Volpini observe que les systèmes d'OpenAI peuvent ne considérer que le début de la représentation vectorielle d'un texte — une réponse perdue au quatrième paragraphe risque d'être écartée dès ce premier passage. Il appelle ça le « paragraphe Matryoshka » : comme des poupées russes, l'essentiel doit tenir dans la première couche. Ouvrez sur l'affirmation ou la définition, pas sur un préambule.
Écrire des passages qui se suffisent à eux-mêmes. Puisque l'extraction se fait phrase par phrase et assemble des fragments, chaque paragraphe doit pouvoir être extrait seul et rester compréhensible. Concrètement : on évite les pronoms flottants — « cette approche », « il » — et on réintroduit l'entité nommée plutôt que d'y renvoyer.
Ancrer les entités, rester factuel. Le grounding privilégie les passages ancrés sur des entités claires et étayés par des éléments vérifiables. Nommez constamment ce dont vous parlez ; appuyez vos phrases sur des chiffres, des dates, des sources nommées. Ce sont autant de points qu'un système peut vérifier — et reprendre.
Garder une intention dominante par page. Une page qui mêle des intentions sans rapport dilue son signal : chacune affaiblit les autres au moment du scoring. Mieux vaut une page centrée sur une intention et un groupe d'entités, et traiter les autres facettes ailleurs.

Reste une question qu'on entend partout : faut-il « structurer » son contenu pour les IA ? Deux lectures circulent, et elles se rejoignent plus qu'elles ne s'opposent. Mike King le montre par la mesure : dans sa démonstration, découper un paragraphe qui traite deux sujets en deux paragraphes monothématiques fait monter la pertinence calculée d'environ 19 %, et y ajouter un titre encore davantage — restructurer sans changer un mot améliore la récupérabilité, et sert aussi le lecteur humain. Pedro Dias rappelle l'autre versant : le découpage en chunks se décide côté moteur, au moment de la récupération, pas dans votre balisage — et un modèle lit le texte en le lisant, pas en cherchant des balises. La recherche académique va dans ce sens : le papier fondateur sur le GEO (Aggarwal et al., KDD 2024) a testé des interventions de contenu — ajouter statistiques, citations, sources, clarifier la formulation — qui améliorent la visibilité de 30 à 40 %, quand le bourrage de mots-clés, lui, passe sous le niveau de départ. Aucun réglage technique dans cette liste.
La synthèse tient en une phrase : la structure qui aide est celle d'une écriture claire. Un paragraphe qui dit une chose, bien, avec sa réponse en tête, est à la fois mieux récupéré et mieux lu. Ce qui n'aide pas, c'est la structure traitée comme un gadget technique, détachée du contenu. Volpini, pourtant défenseur des données structurées, l'admet : on est dans le prolongement du bon SEO, pas dans un nouveau jeu d'astuces GEO.
Un exemple le montre nettement. Le faux levier le plus répandu consiste à servir aux robots une version Markdown « miroir » de ses pages. Otterly l'a testé sur quatorze jours : les fichiers .md ont reçu zéro visite de robot et zéro citation, contre 7,4 % du trafic pour leurs équivalents HTML. Le format n'est pas le levier — je l'ai détaillé dans mon article sur le Markdown. Le levier, c'est ce que vous écrivez.
Tout cela suppose pourtant une condition préalable : que l'IA parvienne seulement à charger votre page. C'est l'objet de la dernière section.
Avant tout ça : être récupérable
Tout ce qui précède suppose une chose : que l'IA parvienne à charger votre page. Ce n'est pas acquis. Avant d'être sélectionné, il faut être atteignable — l'éligibilité précède le classement.
Rappelons le déroulé : un moteur IA décompose la question, identifie des documents candidats, puis va les chercher en temps réel, sous de fortes contraintes de délai. Si l'agent n'arrive pas à charger votre page dans le temps qu'il s'accorde, elle est écartée : elle n'atteint jamais l'étape de sélection des phrases, et ne sera jamais citée. Mike King a mis un nom sur le symptôme : le code 499, que renvoient serveurs et CDN quand le client abandonne avant la fin de la réponse. Il n'apparaît pas dans les outils SEO classiques, d'où l'angle mort. Et l'effet n'est pas une baisse de performance, c'est une exclusion : sur 700 000 pages analysées par Profound, celles qui échouent à répondre plus de trois fois sur quatre reçoivent en moyenne dix-huit fois moins de citations — souvent aucune.
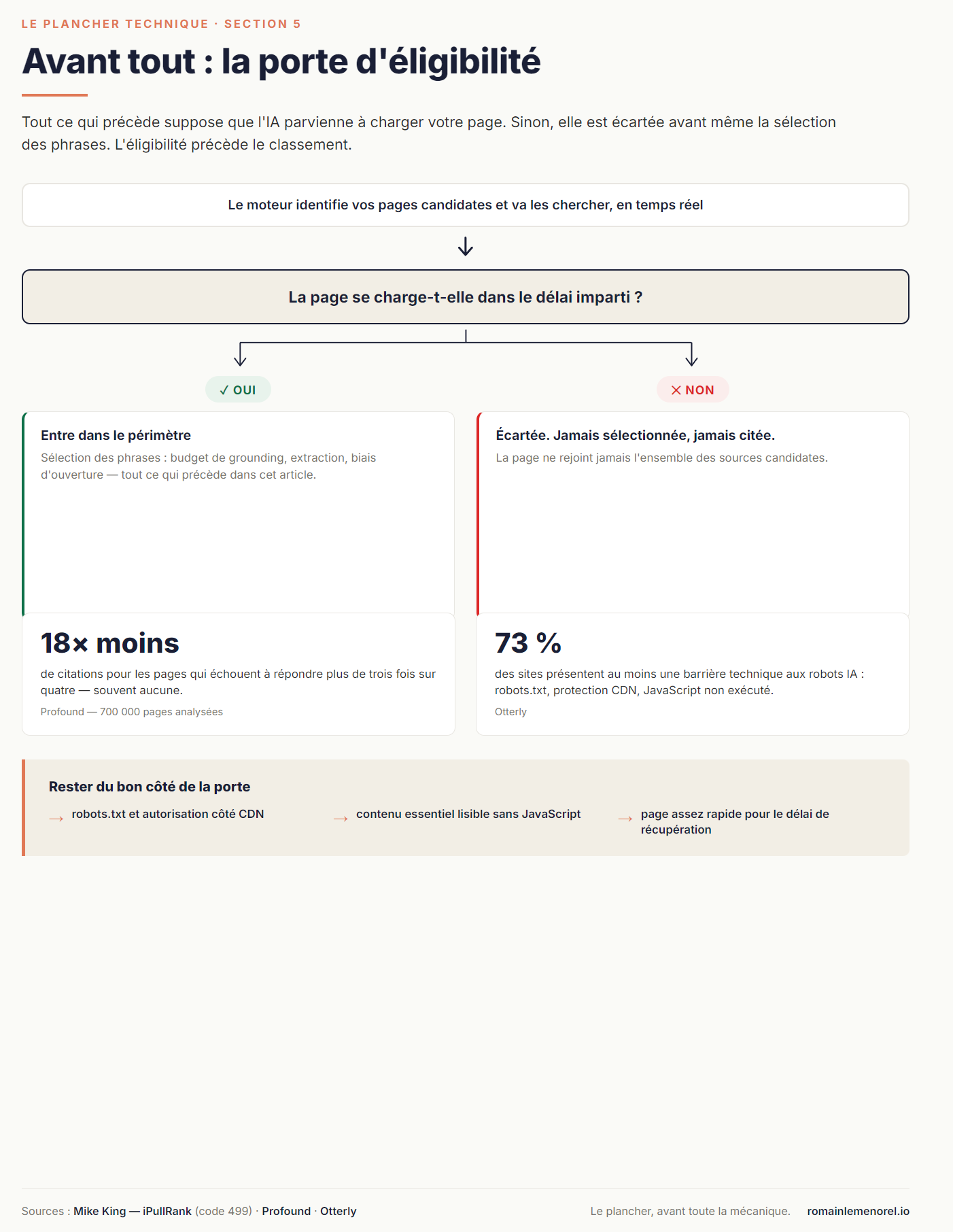
Un second obstacle, plus banal, agit en amont : beaucoup de sites bloquent les robots IA sans le savoir. Otterly relève que 73 % des sites présentent au moins une barrière technique — une règle robots.txt qui interdit les robots IA, une protection CDN qui filtre les agents non-navigateurs, un contenu qui ne s'affiche qu'après exécution d'un JavaScript que ces robots ne lancent pas. Autant de pages qui n'entrent jamais dans le périmètre.
La vérification est simple à poser, même si elle reste technique : assurez-vous que les robots IA peuvent atteindre vos pages (robots.txt, autorisation côté CDN), que le contenu essentiel est lisible sans JavaScript, et que la page se charge assez vite pour survivre au délai de récupération.
Récupérable d'abord, bien écrit ensuite : voilà les deux conditions qui sont sous votre contrôle. Reste une variable qui ne l'est pas — et c'est par elle que je veux conclure.
Pour conclure : au-delà de la page, la fracture du grounding
Résumons. L'IA ne lit pas votre page d'un bloc : elle travaille sur un budget d'environ 2 000 mots, en extrait des phrases, privilégie le haut de page, et ne fait pas remonter les mêmes passages selon la requête et le moteur. La réponse à tout cela n'est pas une checklist technique, c'est une manière d'écrire — claire, avec l'essentiel en tête, en passages qui se tiennent seuls, factuelle — sur une page que l'IA peut effectivement charger. Rien de plus exotique que du bon SEO, rendu simplement plus détectable par les machines.
Mais tout cela suppose une dernière chose, et elle ne dépend pas de vous : que l'IA aille réellement chercher sur le web. Elle ne le fait pas toujours. En analysant les flux de ChatGPT, Andrea Volpini observe que la version gratuite cherche bien moins que la payante — un taux de recherche web de l'ordre de 11 % contre 47 % — et s'appuie davantage sur sa mémoire interne. L'écart n'est pas le vocabulaire : les deux « parlent » des mêmes notions. L'écart, c'est que l'une vérifie et l'autre se souvient. (Échantillon réduit, signal directionnel ; mais le contraste est net, et l'économie pousse dans le même sens — depuis janvier 2026, la recherche est devenue une fonction facturée, et le plan gratuit est routé vers un modèle plus léger.)
Une fracture s'ouvre donc, qui dépasse votre page : entre des réponses ancrées sur des preuves vivantes et des réponses qui reflètent ce que le modèle a retenu. Optimiser la récupération, c'est gagner en visibilité auprès des utilisateurs dont l'IA va chercher. Pour les autres, ce qui compte est plus lent à construire : être une entité claire, stable, suffisamment établie pour que le modèle s'en souvienne sans avoir à chercher. C'est une autre histoire — pour un prochain article.