L'AI Search, c'est en réalité deux mécanismes très différents

On ne compte plus les outils, formations et frameworks qui promettent d'optimiser votre visibilité dans ChatGPT, Perplexity ou l'AI Overview de Google.
Pourtant, quand on examine la mécanique réelle d'une réponse d'IA, on découvre qu'elle repose sur deux processus très différents. Le premier ressemble fortement au SEO que vous pratiquez depuis dix ans : un système choisit dans un index des passages pertinents à la requête. C'est mesurable, reproductible, influençable. Le second est d'une autre nature : à partir des passages récupérés, le modèle recompose une réponse en langage naturel, avec une part d'imprévisibilité irréductible. Deux utilisateurs qui posent la même question peuvent obtenir des formulations différentes, sans que personne n'ait rien optimisé entre les deux.
Une bonne partie de la confusion actuelle vient de l'amalgame entre ces deux mécanismes. On mesure des choses qui ne le sont pas, on agit sur des paramètres hors de portée, et on entretient l'impression d'un nouveau métier là où il s'agit pour l'essentiel d'un renforcement des fondamentaux du SEO.
Cet article pose la distinction, montre ce qui se mesure et ce qui ne se mesure pas, et en tire les conséquences pratiques pour ce qu'on optimise vraiment quand on travaille la visibilité dans les IA.
- Une réponse d'IA est produite par deux mécanismes successifs mais de nature très différente : une phase de récupération qui choisit des passages dans un index, et une phase de génération qui recompose une réponse à partir de ces passages.
- La récupération est déterministe et mesurable. Les facteurs qui font qu'une page est choisie par une IA sont, dans leur immense majorité, ceux qui produisent du trafic SEO : accessibilité technique, qualité et structure du contenu, autorité thématique, positionnement organique.
- La génération est probabiliste : deux utilisateurs posant la même question peuvent obtenir des réponses formulées différemment. Aucune méthode crédible ne permet aujourd'hui de garantir qu'une réponse cite votre page sur une requête donnée à un instant donné.
- Conséquence pratique : optimiser pour les IA, c'est d'abord optimiser la récupération. Le SEO ne disparaît pas avec les moteurs IA. Il devient le mécanisme primaire qui détermine si votre contenu entre dans le périmètre des réponses générées.
- Les outils et frameworks qui promettent une mesure précise de la "visibilité IA" confondent souvent les deux étapes. La posture honnête consiste à mesurer ce qui se mesure, et à investir le reste dans un travail de fond sur les fondamentaux.
Sommaire
- Ce qui se passe quand vous interrogez une IA
- Deux mécanismes très différents enchaînés
- La récupération ancrée : ce qu'on peut influencer
- La génération probabiliste : ce qu'il faut accepter de lâcher
- Ce que ça change concrètement pour la pratique
Ce qui se passe quand vous interrogez une IA
Imaginez que vous tapez dans ChatGPT, Perplexity ou Google AI Mode : "Quels sont les meilleurs écouteurs Bluetooth pour un long trajet en avion ?". Entre le moment où vous appuyez sur "envoyer" et le moment où la réponse apparaît, le système exécute une séquence en quatre temps qui mérite d'être explicitée, parce qu'elle est la base de tout ce qui suit dans cet article.

Étape 1 — L'analyse de votre intention.
Le système ne traite pas votre phrase comme une simple recherche par mots-clés. Il en extrait l'intention sous-jacente : vous cherchez un produit, vous avez un critère de confort (long trajet), une contrainte technique (Bluetooth), un cas d'usage particulier (avion). Cette analyse détermine la suite : une requête factuelle simple comme "quelle est la capitale de l'Espagne ?" aboutira à une réponse rapide ; une requête comparative ou multi-critères comme la nôtre déclenchera une exploration plus large.
Étape 2 — Le query fan-out.
Pour les requêtes complexes, le système ne pose pas une seule question, il en pose plusieurs en parallèle. C'est ce qu'on appelle le query fan-out — littéralement "éclatement de requête" : votre question initiale est décomposée en plusieurs sous-requêtes qui couvrent les différentes facettes du sujet. Notre exemple sur les écouteurs Bluetooth peut générer une douzaine de sous-questions : quelles sont les marques recommandées en 2026 ? quel niveau de confort entre un casque à oreillettes et un serre-tête ? quelle autonomie pour un vol Paris–Tokyo ? quelle qualité de réduction de bruit en cabine ? Et ainsi de suite. Aleyda Solís a documenté un cas e-commerce concret où une seule requête utilisateur sur des écouteurs Bluetooth génère 13 sous-requêtes parallèles, chacune traitée indépendamment.
Étape 3 — La récupération des passages.
Pour chacune de ces sous-requêtes, le système va piocher dans plusieurs sources : index web, Knowledge Graph Google, données produits, avis utilisateurs. Il ne récupère pas des pages entières, mais des fragments — appelés passages — jugés pertinents par rapport à la sous-requête traitée. Chaque sous-requête peut ainsi faire remonter ses propres passages, depuis ses propres sources, indépendamment des autres.
Étape 4 — La synthèse de la réponse.
Une fois tous les passages récupérés, le modèle de langage les assemble pour formuler la réponse que vous voyez s'afficher. C'est lui qui choisit quels passages méritent d'apparaître en premier, lesquels il faut résumer, lesquels il faut citer textuellement, dans quel ordre, avec quelle formulation.
Cette mécanique en quatre temps porte un nom : la Retrieval-Augmented Generation, ou RAG. C'est elle qui structure aujourd'hui le fonctionnement de Google AI Mode, ChatGPT search, Perplexity, Gemini, et la plupart des moteurs de recherche assistés par IA. Avec une particularité essentielle : les étapes 1 à 3 et l'étape 4 ne fonctionnent pas du tout selon la même logique. C'est précisément ce que nous allons examiner maintenant.
Deux mécanismes très différents
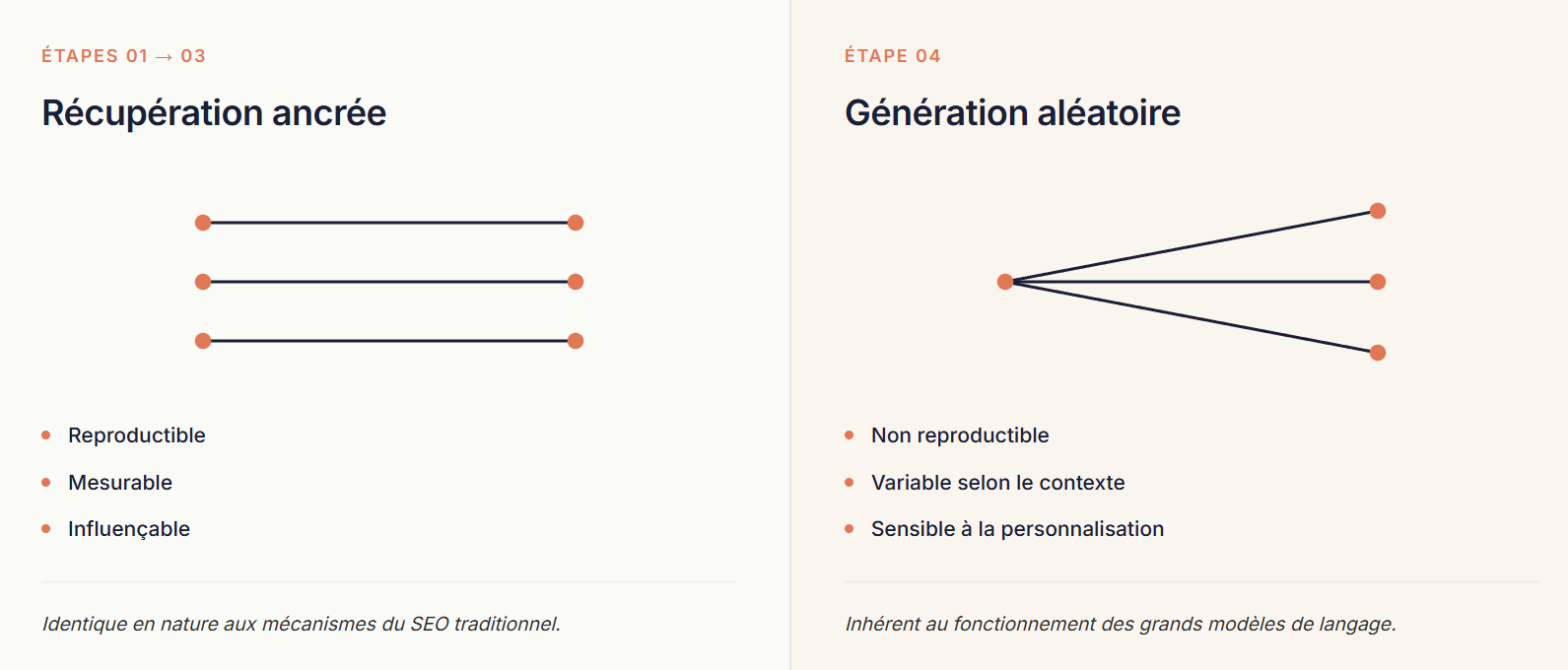
Reprenons les quatre étapes. Les trois premières — analyse de l'intention, query fan-out, récupération de passages — partagent toutes une même propriété : elles sont déterministes. Cela signifie que pour une même requête, dans des conditions identiques, le système produit les mêmes résultats. Si votre page est éligible à la sous-requête "meilleurs écouteurs Bluetooth pour avion 2026" aujourd'hui, elle le sera demain. Si elle ne l'est pas, aucun effet de hasard n'interviendra pour la faire remonter.
Cette première phase a un nom : la récupération ancrée (grounded retrieval). Ancrée, parce que le système puise dans un référentiel concret et vérifiable : un index, un Knowledge Graph, une base produits. Ce sont des opérations de calcul de pertinence, de scoring, de filtrage. Ce sont exactement les opérations que les moteurs de recherche pratiquent depuis vingt ans, transposées dans un nouveau contexte. Les facteurs qui font qu'une page entre dans le périmètre des sources candidates d'une IA sont mesurables, observables, influençables — nous y reviendrons en détail dans la section suivante.
La quatrième étape est d'une nature radicalement différente. Quand le modèle de langage assemble les passages récupérés pour formuler une réponse, il ne suit pas une procédure déterministe. Il choisit le prochain mot, la prochaine portion de phrase, en piochant parmi plusieurs candidats selon des probabilités qu'il a calculées en interne. Le résultat est probabiliste au sens où il n'est pas reproductible : exécuté deux fois à quelques secondes d'intervalle, le même prompt avec les mêmes passages en entrée peut produire deux formulations différentes. Le modèle ne tire pas au hasard pur — il suit des probabilités très précises — mais ces probabilités produisent de la variabilité.
Cette quatrième étape porte aussi un nom : la génération probabiliste (probabilistic generation). Et cette variabilité n'est pas un défaut à corriger : elle est constitutive du fonctionnement des grands modèles de langage. Sans cette propriété, ils ne pourraient pas produire des réponses naturelles, nuancées, adaptées au contexte de chaque conversation.
À cette variabilité interne s'ajoute une couche de personnalisation. La plupart des moteurs IA ajustent leur réponse en fonction de ce qu'ils savent de vous : historique de conversation, préférences observées, contexte de la session. Cette représentation interne que le modèle construit de chaque utilisateur — désignée dans la littérature technique par le terme user embedding — est invisible pour l'utilisateur comme pour l'observateur extérieur. Conséquence directe : deux utilisateurs qui posent la même question peuvent obtenir des réponses différentes, et personne — pas même les ingénieurs qui ont conçu le système — ne peut tracer précisément pourquoi.
Cette dissymétrie entre les deux phases du RAG est le cœur de tout ce qui suit dans cet article. La récupération est une mécanique que vous pouvez comprendre, influencer, mesurer. La génération est une mécanique que vous pouvez nourrir avec du contenu de qualité, mais dont la sortie ne sera jamais entièrement sous votre contrôle. Cette distinction simple change radicalement la posture à tenir face aux promesses du marché.
La récupération ancrée : ce qu'on peut influencer
C'est sur la phase de récupération que se joue la majeure partie du travail d'optimisation pour les IA. Le mécanisme n'est pas nouveau : c'est celui du SEO classique, transposé à un contexte où les sources candidates ne sont plus présentées au lecteur sous forme de dix liens bleus, mais sélectionnées par un système pour alimenter une réponse synthétique.
Première condition : que votre page existe pour le système.
Avant tout calcul de pertinence, le crawler de l'IA doit pouvoir atteindre votre page, la charger, l'analyser. Mike King a forgé une formule qui synthétise bien la chose : "Eligibility is the new ranking" — l'éligibilité est le nouveau classement. Si votre page met trop de temps à répondre à un crawler IA, ou si elle bloque ces crawlers par erreur dans son robots.txt, elle ne sera jamais candidate à une citation, quelle que soit la qualité de son contenu. Une étude de Profound portant sur 700 000 pages a montré que celles qui dépassent un certain seuil d'erreurs d'accès reçoivent en moyenne 18 fois moins de citations que les pages stables.
Deuxième condition : que votre page rank en organique.
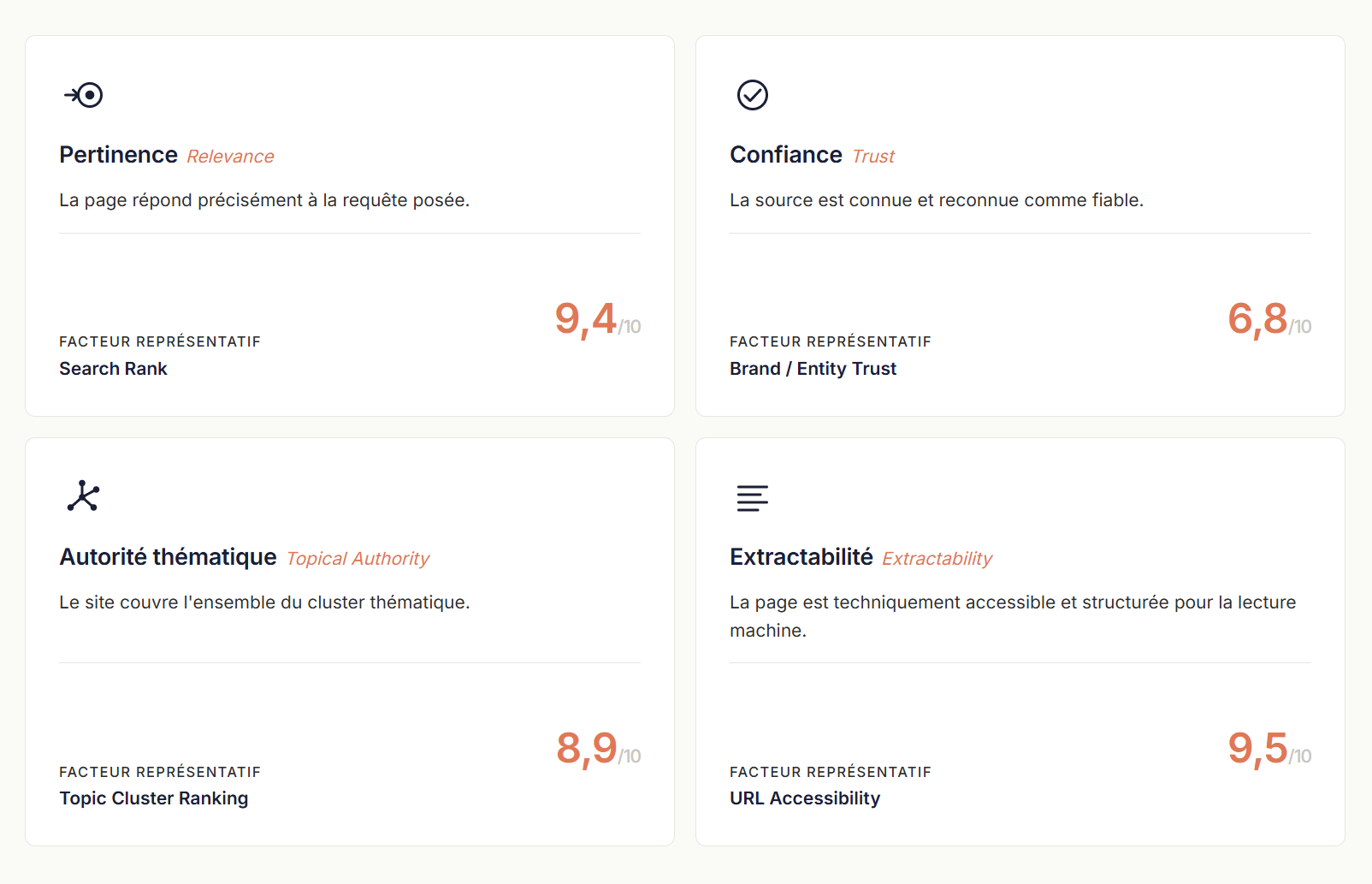
Une fois éligible, votre page entre dans le périmètre des sources candidates. Et ce périmètre, dans la plupart des cas, est directement dérivé du classement organique. Lily Ray a documenté de manière convergente que les principaux moteurs IA — ChatGPT, Perplexity, Gemini, AI Overviews — s'appuient massivement sur l'index Google pour leur phase de récupération. Cyrus Shepard, dans sa méta-analyse de 54 études sur les facteurs de citation IA, attribue au Search Rank un score de 9,4 sur 10 — l'un des trois facteurs les plus déterminants identifiés à date.
Troisième condition : que votre page rank sur les sous-requêtes du fan-out.
Vous n'optimisez plus seulement pour une requête principale, mais pour un faisceau de sous-requêtes que l'IA peut générer autour d'elle. Cyrus Shepard désigne ce facteur sous le terme de Fan-out Rank et lui attribue 9,3 sur 10. Concrètement, votre couverture thématique devient le levier le plus structurant : une page qui traite plusieurs facettes d'un sujet a beaucoup plus de chances d'être citée qu'une page focalisée sur un seul mot-clé.
Ces trois conditions se résument en quatre piliers que Cyrus Shepard a formalisés à partir de ses 54 études : Pertinence (Relevance), Confiance (Trust), Autorité thématique (Topical Authority), Extractabilité (Extractability — c'est-à-dire l'accessibilité technique et la structure de la page). Ces piliers ne sont pas une rupture : ce sont les fondamentaux du SEO qualitatif, renforcés et reformulés pour un contexte où le lecteur de votre page est devenu une machine.
Je ne déroule pas ici les 23 critères mesurés dans cette méta-analyse — ce travail fait l'objet d'un article dédié sur ce blog. Une donnée parlante suffit à fixer l'idée : selon une étude propriétaire d'iPullRank sur 79 000 paires URL-requête, les pages optimisées pour la densité d'entités sur les requêtes mid-tail (de longueur intermédiaire entre le mot-clé court et la longue traîne) enregistrent +292 % de probabilité de citation par rapport à la moyenne. Pas une vague corrélation : un effet massif et reproductible.
La récupération ancrée est mesurable, influençable, et déjà bien documentée empiriquement. Tout ce que vous faites de bien en SEO produit aujourd'hui des effets directs sur votre visibilité dans les IA. Le travail ne change pas de nature : il change de surface d'application. Reste à examiner ce qui se passe une fois que vos passages sont récupérés — la partie sur laquelle vous n'avez aucune prise directe.
La génération probabiliste : ce qu'il faut accepter de lâcher
Une fois les passages récupérés, le modèle de langage prend le relais. C'est ici que la mécanique change radicalement de nature. Trois facteurs combinés rendent cette étape non reproductible.
Le premier est interne au modèle.
Comme nous l'avons vu, il choisit ses mots selon des probabilités calculées en interne, ce qui produit de la variabilité entre deux exécutions, même pour des entrées strictement identiques. Cette propriété est constitutive du fonctionnement des grands modèles de langage : elle n'est pas un paramètre que vous pouvez désactiver.
Le deuxième est la personnalisation.
Chaque utilisateur dispose d'une représentation interne — son user embedding — que le modèle exploite pour ajuster sa réponse. Historique de conversation, préférences inférées, contexte de la session : autant de variables qui modifient la sortie sans que personne ne puisse les inspecter de l'extérieur. Une même requête, posée dans deux sessions différentes par deux utilisateurs aux profils contrastés, peut produire des réponses sensiblement divergentes — y compris dans le choix des sources citées.
Le troisième est l'état mouvant de l'index.
Une page indexée aujourd'hui peut être déclassée demain. Une source concurrente peut publier un contenu meilleur et déplacer votre page hors du périmètre des candidates. Ce que l'IA récupère aujourd'hui n'est pas nécessairement ce qu'elle récupérera demain pour la même question.
La conséquence pratique est nette : il n'existe pas, à ce jour, de méthode crédible pour garantir qu'une réponse d'IA citera votre page sur une requête donnée, à un instant donné. Les outils qui annoncent des "rangs ChatGPT" ou des "scores de visibilité IA" précis font ce qu'ils peuvent avec un signal intrinsèquement instable. Ce n'est pas une critique de ces outils : certains apportent une vraie valeur d'indication de tendance. Mais il faut comprendre ce qu'ils peuvent et ne peuvent pas mesurer. Suivre la fréquence à laquelle votre marque apparaît sur un échantillon de requêtes, oui. Garantir une citation sur telle requête à telle heure, non.
Une étude publiée par Oumi pour le New York Times en avril 2026, portant sur 4 326 tests de Google AI Overviews, a même montré que 56 % des bonnes réponses générées par Gemini 3 étaient non ancrées : la source citée par le modèle ne contenait pas, en réalité, l'information avancée dans la réponse. Le modèle avait retrouvé la bonne information, mais il l'avait associée à une source qui ne la portait pas. Cette donnée n'invalide pas la mécanique de la récupération — elle rappelle que la phase de génération introduit une part d'aléa que personne n'a entièrement maîtrisée à ce stade.
La posture à tenir face aux décideurs découle naturellement de cette analyse : "Voici ce qui produit de la visibilité dans la phase de récupération, voici notre performance sur ces facteurs, et voici les indicateurs de tendance qu'on suit côté génération. Ce qui se joue dans la formulation finale d'une réponse n'est pas directement pilotable — et c'est normal." C'est une position honnête, défendable, et qui laisse intacte la valeur du travail de fond — un travail qui prend même, comme on va le voir maintenant, un poids renouvelé.
Ce que ça change concrètement pour la pratique
Une fois la mécanique posée, les conséquences pratiques s'enchaînent. La formulation la plus logique pour décrire cette position tient en une phrase : optimiser pour les IA, c'est d'abord optimiser la récupération. Le SEO ne ne s'efface pas — il devient le mécanisme primaire qui détermine si votre contenu entre dans le périmètre des réponses générées. Cyrus Shepard, au terme de sa méta-analyse, formule la chose autrement : "win SEO, win AI citations". La convergence est largement plus forte que la rupture.
Trois conséquences pratiques en découlent.
1. Renforcer les fondamentaux SEO dans tous leurs aspects.
Crawlabilité, accessibilité technique, performance, qualité éditoriale, structure de contenu, autorité thématique : tous ces signaux sont aujourd'hui les premiers prédicteurs de votre visibilité dans les IA. Les cinq premiers facteurs de citation IA dans la méta-analyse Shepard sont tous des fondamentaux SEO. Ce que vous faites de bien en SEO produit des effets directs sur les IA. Ce n'est pas une intuition — c'est le constat qui convergent des principales études publiées en 2025 et 2026.
2. Concevoir vos contenus par facette, pas par mot-clé.
Le query fan-out introduit une nuance importante par rapport à la pratique classique : une page ne ranke plus sur une requête principale, elle ranke sur un groupe de sous-requêtes. La conséquence éditoriale est nette. Sur un sujet donné, il faut anticiper les facettes que l'IA va explorer — facteurs de décision, alternatives, contraintes, cas particuliers — et y répondre en profondeur, soit dans une page exhaustive, soit dans un cluster de pages liées. Aleyda Solís résume la bascule par une formule simple : passer d'une logique "answer a query" à une logique "answer a facet". La couverture thématique devient une condition d'éligibilité aux citations IA.
3. Choisir où vous investissez vos efforts
C'est probablement la décision la plus importante à court terme. Côté récupération, le travail est mesurable : indicateurs Search Console, positions organiques sur les sous-requêtes du fan-out, présence dans les sources citées par les principaux moteurs IA, fréquence d'apparition de votre marque sur un échantillon de requêtes représentatives. Côté génération, on suit des tendances, pas des classements précis. Mieux vaut consacrer son énergie à mesurer ce qui est fiable — performance des fondamentaux et présence améliorée dans les sources.
Un point mérite d'être noté côté indicateurs business : les nouveaux comportements utilisateurs (zero-click, sessions multi-tours, mentions de marque non liées) génèrent de la valeur réelle, mais cette valeur ne se mesure plus avec les seuls KPIs SEO traditionnels. Trafic référents depuis les moteurs IA, conversions, part de voix dans un corpus de requêtes : autant d'indicateurs à mettre en place progressivement, en acceptant qu'ils soient moins précis que les métriques du web analytics classique, mais qu'ils racontent un signal qui compte de plus en plus.
Pour conclure : un déplacement d'équilibre, pas une rupture
Ce qui ressemble à une rupture est en réalité un déplacement d'équilibre. Avant l'AI Search, la phase de récupération prenait l'essentiel du poids et le SEO portait à peu près tout ce qu'il y avait à porter. Avec les moteurs IA, la phase de génération prend une place nouvelle — et elle introduit une part d'imprévisibilité qu'il faut accepter de ne pas maitriser.
La bonne nouvelle, c'est que la partie qui compte le plus pour entrer dans les réponses des IA reste celle que vous savez travailler. Crawlabilité, qualité éditoriale, autorité thématique, couverture par facette : ces leviers fonctionnent, ils sont mesurables, et les études convergent pour montrer qu'ils restent les premiers prédicteurs de la visibilité dans les IA. Ce qu'il faut retenir c'est la distinction claire entre les deux phases : ce qui se mesure et ce qui ne se mesure pas.
Cette distinction est le premier maillon d'une série que je veux mener cette année sur ce blog. Deux articles suivent directement celui-ci. Le premier creusera la phase de récupération sous un angle moins évident qu'on ne le pense : votre site ne sert plus un seul type de bot, mais quatre — crawlers classiques, pipelines RAG, navigateurs agentiques, crawlers d'entraînement —, chacun avec ses contraintes propres, parfois contradictoires. Le second prendra de la hauteur sur l'écosystème lui-même : comment la catégorie "GEO" a été fabriquée, par qui, dans quel intérêt — et ce que cela change pour la lecture du marché actuel.
Sources citées dans cet article
Sources officielles
- Google Patents — US20240289407A1, Search with Stateful Chat
- Google Patents — WO2024064249A1, Systems and Methods for Prompt-Based Query Generation for Diverse Retrieval
Analyses et études du secteur
- Pedro Dias, Your AI Strategy Isn't a Strategy — It's SEO With a Rebrand, The Inference, novembre 2025 — theinference.io
- Mike King, How AI Mode Works and How SEO Can Prepare for the Future of Search, iPullRank, mai 2025 — ipullrank.com
- Mike King, Quick Tip: How Page Speed Impacts ChatGPT and Perplexity Visibility, iPullRank, mai 2026 — ipullrank.com
- Aleyda Solís, Google AI Mode's Query Fan-Out Technique: What Is It and How Does It Mean for SEO?, aleydasolis.com, mai 2025 — aleydasolis.com
- Francine Monahan, Beyond Rankings: Designing AI Search Metrics for the Next Era of SEO, iPullRank, mars 2026 — ipullrank.com
- Lily Ray, Your GEO Strategy Might Be Destroying Your SEO, Substack, mars 2026 — lilyraynyc.substack.com
- Cyrus Shepard, AI Citation Ranking Factors Analysis, Zyppy Signal, mai 2026 — signal.zyppy.com
Investigation indépendante
- How Accurate Are Google's AI Overviews?, The New York Times (étude réalisée par Oumi), avril 2026 — nytimes.com