Citations IA : ce que disent vraiment les 54 études compilées par Cyrus Shepard
Lecture critique de la méta-analyse de Cyrus Shepard sur les 23 facteurs de citations IA, prolongée par un découpage en 5 familles opérationnelles et des sources récentes qui actualisent le débat.
Tout le monde s'accorde sur le constat : la visibilité dans les réponses générées par les moteurs IA — Google AI Overviews, AI Mode, ChatGPT, Perplexity, Gemini — devient un enjeu de premier rang. Mais sur les leviers concrets pour y arriver, le paysage reste fragmenté. Une étude par-ci, une expérimentation par-là, des frameworks contradictoires, des promesses parfois douteuses : il manquait une vue d'ensemble.
Cyrus Shepard a comblé ce manque le 7 mai 2026 en publiant sur Zyppy Signal une méta-analyse de 54 études, brevets et expérimentations sur les facteurs qui influencent les citations IA. Le résultat : une grille de 23 facteurs, chacun scoré sur trois critères — répétabilité des observations, force des preuves, support officiel par les plateformes. Une consolidation pondérée plutôt qu'une énième liste à la mode.
Ce que Shepard a produit est précieux. Mais une méta-analyse de ce type a deux limites par construction : elle photographie un état des publications à un instant T, et elle laisse une partie du terrain à découvert pour le lecteur opérationnel. La donnée principale de Shepard sur la corrélation top 10 / citations IA date de juillet 2025 ; depuis, les chiffres ont massivement évolué. Le débat sur les données structurées mérite plus que les quelques lignes qu'il y consacre. Et certains "faux amis" comme LLMs.txt méritent qu'on rétablisse la vérité.
C'est l'objet de cet article : prolonger le travail de Shepard avec une lecture critique étayée, un découpage opérationnel en cinq familles de leviers, et des sources additionnelles qui actualisent ou nuancent ses conclusions.
Cyrus Shepard a agrégé 54 études, brevets et expérimentations en une grille pondérée de 23 facteurs de classement pour les citations IA. Sa thèse centrale : "win SEO, win AI citations (most of the time, with extra steps)".La corrélation top 10 / citations IA, donnée fondatrice de Shepard, s'est effondrée en sept mois : 76% (Ahrefs, juillet 2025) → 38% (Ahrefs, février 2026) → 17% (BrightEdge, février 2026). Le passage à Gemini 3 et la généralisation du fan-out changent la donne.Cinq familles opérationnelles permettent de transformer la grille de Shepard en plan d'action : accessibilité technique, performance dans la recherche, structure et formulation du contenu, signaux de confiance et d'entité, faux amis.L'EEAT a basculé sur les surfaces IA : il ne joue plus seulement comme modificateur de ranking, mais comme filtre de citation à part entière.Les "faux amis" comme LLMs.txt (score 2/10 chez Shepard) ou un usage purement défensif du schéma de données restent des paris asymétriques à faible coût, pas des piliers stratégiques.
Sommaire
- Ce que Shepard a fait, et pourquoi son article compte
- Un découpage opérationnel des 23 facteurs en cinq familles
- Famille 1 — Accessibilité technique : ce qui se décide en amont
- Famille 2 — Performance dans la recherche : le pont SEO/GEO qui se déplace
- Famille 3 — Structure et formulation du contenu : ce qui se joue dans la page
- Famille 4 — Signaux de confiance et d'entité : l'EEAT en première ligne
- Famille 5 — Les faux amis : rétablir la vérité
- Synthèse : quatre chantiers pour piloter sa visibilité IA
1. Ce que Shepard a fait, et pourquoi son article compte
Cyrus Shepard est un nom familier de la communauté SEO. Fondateur de Zyppy SEO, ancien responsable contenu chez Moz, il publie depuis plus de quinze ans sur l'analyse data des facteurs de ranking. Son article du 7 mai 2026 s'inscrit dans cette continuité, transposée à un terrain neuf : les citations IA.
Sa méthode est rigoureuse et explicitée. Shepard a téléchargé "presque toutes" les expérimentations, études et brevets publiés sur le sujet ces deux dernières années, puis a restreint son corpus aux 54 sources les plus solides et les plus pertinentes. Il a ensuite catégorisé les observations, croisé les résultats, et identifié les patterns qui revenaient le plus souvent. Chaque facteur s'est vu attribuer un score sur trois critères :
- Répétabilité : combien d'études convergent sur ce constat, et avec quelle cohérence de résultats ?
- Force des preuves : une étude de 50 millions de requêtes pèse plus qu'un case study à 10 requêtes.
- Support officiel : le facteur est-il documenté dans des sources officielles, des spécifications techniques ou des brevets ?
Le scoring final est artisanal — Shepard l'assume — et il le précise avec une honnêteté qui mérite d'être saluée. Il rappelle d'ailleurs explicitement que les 23 facteurs identifiés ne sont pas des "ranking factors" au sens traditionnel, mais des caractéristiques de contenu corrélées avec les citations IA à travers les études. Corrélation, pas causalité. Cette nuance est fondamentale pour la suite.
Sa thèse centrale tient en une phrase : "win SEO, win AI citations (most of the time, with extra steps)". Autrement dit, l'optimisation pour les citations IA s'appuie en grande partie sur les fondamentaux SEO existants, avec quelques ajustements et quelques chantiers spécifiques. La rupture méthodologique est moindre qu'on ne le dit souvent.
Cette thèse a sa force, et elle a ses limites. Sa force : elle évite les fausses promesses d'un nouveau toolkit miracle. Ses limites : elle adoucit deux tendances qu'on observe dans les données les plus récentes, à savoir l'effritement de la corrélation entre top 10 et citations IA, et la montée en puissance d'autres signaux moins SEO-classiques que ce que Shepard suggère. C'est précisément l'angle qu'on creuse à partir de la prochaine section.
2. Un découpage opérationnel des 23 facteurs en cinq familles
Shepard propose en conclusion de son article une synthèse en quatre catégories conceptuelles : Relevance, Trust, Topical Authority et Extractability. Le découpage est élégant, et il a son utilité pour penser. Il a en revanche un défaut : il mélange des leviers qui n'appellent pas les mêmes actions. Une recommandation sur l'accessibilité des bots IA et une recommandation sur la formulation des passages d'un article ne mobilisent ni les mêmes équipes, ni les mêmes outils, ni les mêmes temporalités.
Pour passer de la grille de Shepard à un plan d'action, on propose un découpage différent : cinq familles opérationnelles, chacune correspondant à un type de levier et à un terrain d'intervention distinct.

- Famille 1 — Accessibilité technique.
Tout ce qui détermine, en amont de toute analyse de contenu, si vos pages sont visibles par les moteurs IA. Action principale : audit infra et configuration. (URL Accessibility, Preview Control, Content Visibility, Language)
- Famille 2 — Performance dans la recherche.
Tout ce qui relève de votre positionnement dans la recherche classique et étendue. Action principale : stratégie SEO et couverture thématique. (Search Rank, Fan-out Rank, Topic Cluster Ranking, Domain Authority, Known Source)
- Famille 3 — Structure et formulation du contenu.
Tout ce qui se joue dans la page, dans le rapport entre la requête, la structure du contenu et sa formulation. Action principale : standards éditoriaux et templates de rédaction. (Query-Answer Match, Intent-Format Match, Answer Near the Top, AI-ready Structure, Factually Specific, Explicit Phrasing, Self-Contained Passages, Length, Freshness, Cites Sources)
- Famille 4 — Signaux de confiance et d'entité.
Tout ce qui ancre votre marque, vos auteurs et vos contenus dans un écosystème d'autorité reconnaissable. Action principale : RP, gestion d'entité et EEAT. (Brand/Entity Trust, Entity Consistency)
- Famille 5 — Faux amis.
Les facteurs sur lesquels la communauté investit sans que les preuves suivent. Action principale : arbitrage rationnel coût/bénéfice. (Structured Data, LLMs.txt, et dans une certaine mesure Domain Authority)
Le visuel ci-dessous cartographie les 23 facteurs dans ces cinq familles, avec leur score Shepard. Il donne en une vue la grille complète qui sert de fil rouge pour la suite de l'article.
À noter avant d'entrer dans le détail : deux facteurs sont volontairement placés dans plusieurs zones d'analyse. Domain Authority apparaît à la fois en Famille 2 (parce qu'il influence le ranking classique) et en Famille 5 (parce que sa corrélation directe avec les citations IA est faible). Freshness est intégré à la Famille 3 (formulation/structure éditoriale), mais sa logique relève autant d'une discipline de mise à jour que de rédaction pure. Ces chevauchements ne sont pas des défauts du modèle, ils traduisent la réalité multi-dimensionnelle de plusieurs leviers.
3. Famille 1 — Accessibilité technique : ce qui se décide en amont
C'est le pré-requis silencieux. Un contenu parfaitement rédigé, structuré et autoritaire ne sera jamais cité s'il n'est pas accessible au moment où l'IA en a besoin. Cette famille est en haut de la grille de Shepard pour une raison : ses facteurs sont des conditions binaires, des passages obligés. URL Accessibility (9.5) et Preview Control (9.2) sont respectivement le premier et le quatrième facteur du classement, ce n'est pas un hasard.
Connaître et arbitrer le paysage des AI crawlers
En 2026, le web est crawlé par plusieurs catégories de bots IA aux logiques différentes, et c'est là que se joue le premier arbitrage.
- Les bots d'entraînement récupèrent du contenu pour nourrir les modèles : GPTBot pour OpenAI, ClaudeBot pour Anthropic, Google-Extended pour les modèles Google. Les bloquer ne réduit pas directement vos citations live, mais limite la "connaissance" que le modèle aura de votre marque sur le long terme.
- Les bots de recherche temps réel récupèrent des pages au moment où une requête est formulée : OAI-SearchBot et ChatGPT-User pour OpenAI, PerplexityBot pour Perplexity, Googlebot pour les AI Overviews. Bloquer ces bots est l'erreur la plus coûteuse : c'est couper le robinet des citations là où elles se jouent.
L'arbitrage classique consiste à autoriser les bots de recherche temps réel et à arbitrer plus finement les bots d'entraînement selon votre modèle économique (un média sous paywall a des raisons légitimes de bloquer GPTBot que n'a pas un site SaaS qui veut être recommandé).
Les documentations officielles à connaître pour configurer proprement votre robots.txt :
- OpenAI — User agents and bots
- Anthropic — ClaudeBot user agents
- Google — Google-Extended overview
- Perplexity — PerplexityBot
# === Bots de recherche temps réel — citations IA live ===
# Recommandation : autoriser sans restriction
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: PerplexityBot
Allow: /
# === Bots d'entraînement ===
# Arbitrage selon votre modèle :
# - Sites SaaS, B2B, éditoriaux qui cherchent la recommandation : autoriser
# - Médias sous paywall, contenu premium : bloquer ou restreindre
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: Google-Extended
Allow: /
# === Variante défensive (à activer en remplacement si applicable) ===
# User-agent: GPTBot
# Disallow: /
#
# User-agent: ClaudeBot
# Disallow: /
#
# User-agent: Google-Extended
# Disallow: /Surveiller les directives qui limitent l'extraction
Même quand les bots sont autorisés, des directives plus subtiles peuvent réduire mécaniquement votre visibilité IA. Les balises nosnippet, data-nosnippet et l'attribut max-snippet indiquent à Google et Bing de ne pas afficher (ou de limiter) le texte extrait d'une page dans les snippets et les surfaces IA. Pour les pages que vous voulez voir citées, ces directives doivent être absentes — ou réservées à des zones très précises que vous ne souhaitez pas voir reprises.
Auditer la visibilité réelle du contenu
Un autre piège classique : du contenu présent dans le HTML mais inaccessible sans interaction utilisateur. Onglets fermés par défaut, accordéons, contenu chargé en JavaScript après le rendu initial, divs masqués via CSS sans dépliement automatique. Plusieurs études ont confirmé que les moteurs IA partagent le biais déjà bien documenté de Google : le contenu non immédiatement visible est moins bien valorisé, et parfois purement ignoré dans l'extraction. La règle pratique : tout ce qui doit être cité doit être visible dans le HTML rendu, sans clic.
Le piège Cloudflare et des WAF agressifs
C'est l'angle mort le plus fréquent en 2026, et probablement le plus dommageable. De nombreux sites bloquent involontairement les bots IA via leur Web Application Firewall, leurs règles de bot management Cloudflare, ou des protections "AI scraper" activées par défaut sans audit. Vous pouvez avoir un robots.txt parfaitement permissif, et bloquer GPTBot, OAI-SearchBot ou PerplexityBot au niveau edge sans le savoir. Vérifier les logs serveur pour confirmer que ces user-agents reçoivent bien des réponses 200 fait partie de l'audit minimum.
Et la langue dans tout ça
Le facteur Language (6.3) que Shepard intègre dans son top 20 traduit une réalité simple : les moteurs IA biaisent vers la langue de la requête et, souvent, vers la localisation de l'utilisateur. Pour une marque qui adresse plusieurs marchés, la conséquence est claire : disposer de versions linguistiques natives bien servies (pas de traduction approximative) reste un levier d'éligibilité aux citations sur chaque marché.
4. Famille 2 — Performance dans la recherche : le pont SEO/GEO qui se déplace
C'est ici que la thèse de Shepard porte le plus, et c'est aussi ici qu'elle mérite d'être prolongée. Cinq facteurs de sa grille relèvent de cette famille : Search Rank (9.4), Fan-out Rank (9.3), Topic Cluster Ranking (8.9), Known Source (5.4) et Domain Authority (5.0). Les deux premiers scores expliquent pourquoi son TL;DR insiste sur la continuité avec le SEO classique. Mais les données les plus récentes racontent une histoire un peu différente.
La corrélation top 10 / citations IA, sept mois plus tard
L'argument principal de Shepard repose sur la corrélation entre rang Google et citations IA. La donnée souvent citée vient d'une étude Ahrefs de juillet 2025 sur 1,9 million de citations : 76% des URLs citées dans les AI Overviews appartenaient au top 10 organique pour la même requête. À cette époque, le raccourci "ranker = être cité" tenait à peu près.
Sept mois plus tard, cette corrélation s'est sensiblement effritée. Voici la séquence d'études consolidées :
| Période | Source | Top 10 / citations AIO |
|---|---|---|
| Fin 2024 | Multiple studies | ~75% |
| Juillet 2025 | Ahrefs (1,9 M citations) | 76% |
| Octobre 2025 | BrightEdge | 54% |
| Février 2026 | Ahrefs (863K SERPs / 4M URLs) | 38% |
| Février 2026 | BrightEdge | 17% |
L'écart entre les deux mesures de février 2026 traduit des méthodologies différentes, pas une contradiction de fond : les deux pointent dans le même sens. La chute est confirmée également par Search Engine Journal, qui souligne deux explications convergentes : un upgrade massif vers Gemini 3 comme moteur par défaut des AI Overviews en janvier 2026, et une généralisation du fan-out. L'analyse de SE Ranking indique que Gemini 3 a remplacé environ 42% des domaines précédemment cités et délivre 32% de sources supplémentaires par réponse par rapport à son prédécesseur.
Ce qu'il faut retenir : ranker top 10 reste un avantage, mais ne suffit plus. Le top 10 organique est désormais une condition nécessaire et de moins en moins suffisante pour gagner des citations.
Le fan-out : ce qui change vraiment
Le Fan-out Rank est le troisième facteur de Shepard (score 9.3), et c'est probablement le mécanisme le moins compris en dehors du cercle des SEO les plus pointus. Le principe est documenté dans deux brevets Google déposés sur les dernières années : Search with Stateful Chat (US20240289407A1) et Thematic Search.
Le fonctionnement est le suivant. Quand un utilisateur formule une requête à AI Mode ou déclenche un AI Overview, le système ne se contente pas de chercher cette requête. Un modèle de langage décompose la requête en plusieurs sous-requêtes thématiques (entre 5 et plusieurs dizaines selon la complexité), exécutées en parallèle. Ces sous-requêtes explorent des facettes adjacentes du sujet : comparaisons, variantes, sous-intents, entités liées. Les résultats de toutes ces requêtes sont ensuite synthétisés en une réponse unique avec citations.
Pour reprendre l'exemple classique d'Aleyda Solís : une requête initiale "best wireless headphones for running" peut générer des fan-outs sur "wireless headphones battery life", "headphones sweat-resistant", "wireless earbuds vs over-ear running", etc. Votre page peut très bien ne pas ranker pour la requête principale et pourtant être citée parce qu'elle ranke top 3 sur une sous-requête. C'est précisément ce que documente une autre étude Ahrefs : ChatGPT Search cite des pages en position 21 et au-delà environ 90% du temps, et seulement 12% des URLs citées par ChatGPT, Perplexity et Copilot rankent en top 10 de la requête originale.
L'implication stratégique est nette : la couverture thématique remplace progressivement le ranking unique comme métrique pertinente. Topic Cluster Ranking (8.9) chez Shepard formalise ce passage. Travailler en clusters de sous-intents, avec un maillage interne qui couvre les variantes naturelles d'une thématique, devient plus rentable qu'un effort concentré sur une seule page tête de cluster.
Domain Authority à 5/10 : pourquoi un classique du SEO décroche
Dernier signal intéressant de cette famille : Shepard place Domain Authority à 5.0 — score faible pour un indicateur historiquement central en SEO. La nuance est importante. Plusieurs études ont cherché une corrélation entre DA et citations IA et l'ont trouvée, mais faible et inconsistante. La raison probable : les moteurs IA s'appuient davantage sur des signaux d'entité (mentions, cohérence cross-sources, présence Wikipedia/Knowledge Graph) que sur la popularité par liens au sens classique. Le Known Source (5.4) — le fait que l'URL soit déjà connue de l'IA via ses données d'entraînement — joue dans le même registre : la mémoire entité prime sur le link graph.
Domain Authority reste pertinent indirectement, parce qu'il influence le ranking organique qui, lui, influence encore les citations. Mais comme levier direct, il n'est plus là où on l'attendait.
En pratique
Trois chantiers prioritaires pour cette famille :
- Penser votre couverture en clusters de sous-intents plutôt qu'en pages isolées. Identifier les fan-outs probables de vos requêtes cibles (via SERP analysis, "People Also Ask", outils dédiés comme AlsoAsked) devient une routine éditoriale.
- Maintenir un maillage interne dense entre les pages d'un même cluster pour que l'IA navigue facilement de sous-intent en sous-intent.
- Investir sur les signaux d'entité (cf. Famille 4) en complément du link building classique. Le SEO de 2026 reste utile, mais il a un nouvel étage.
5. Famille 3 — Structure et formulation du contenu : ce qui se joue dans la page
Dix facteurs de la grille de Shepard relèvent de cette famille — c'est l'ensemble le plus dense, et c'est aussi le plus actionnable. Ce sont des décisions de rédaction prises page par page. Pour rendre le tout lisible, on les regroupe en quatre principes et on les présente dans une vue de synthèse.
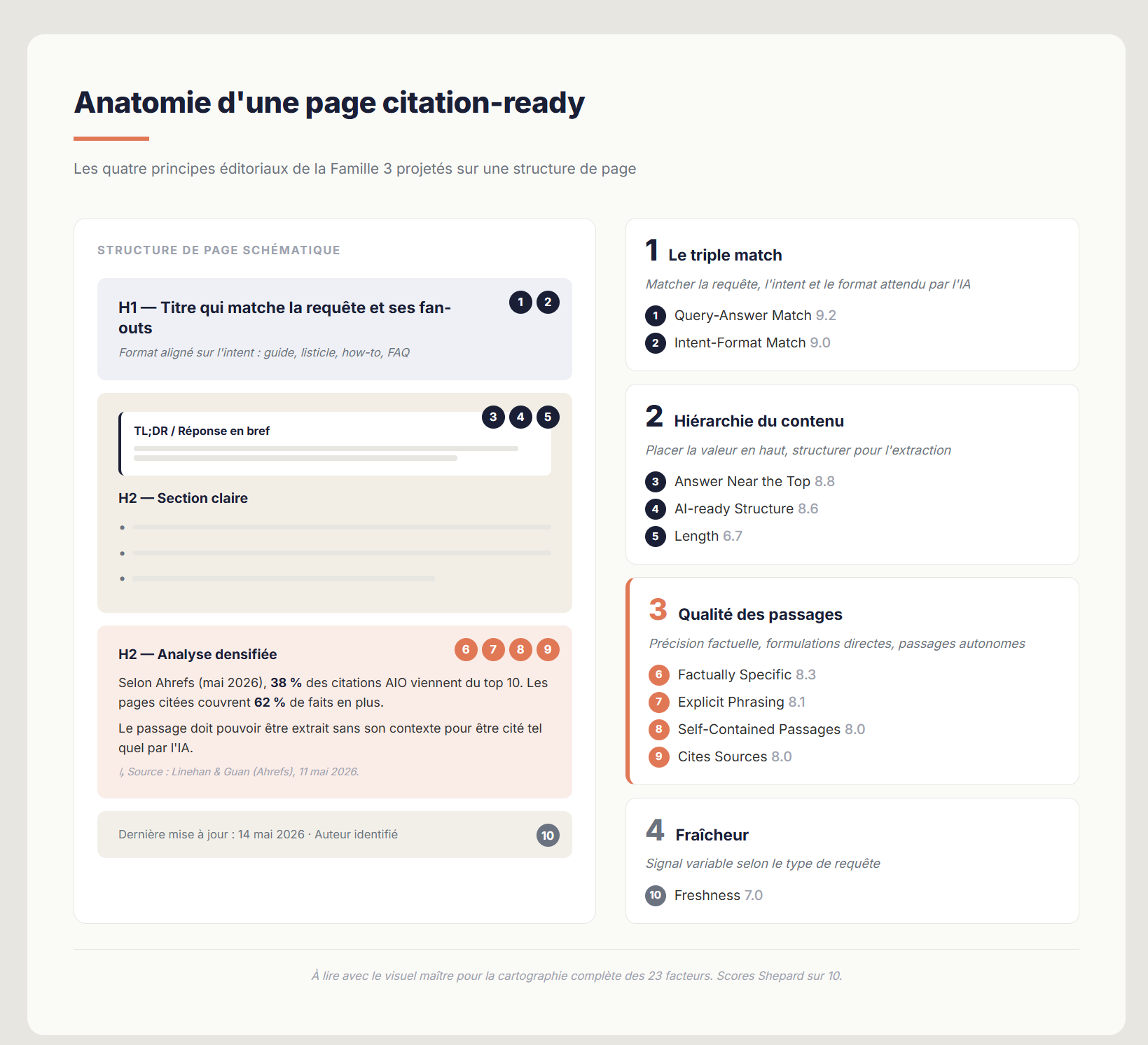
| Principe | Facteur Shepard | Score | À retenir |
|---|---|---|---|
| Triple match | Query-Answer Match | 9.2 | Titre, sous-titres et contenu reprennent la sémantique de la requête et de ses fan-outs probables |
| Intent-Format Match | 9.0 | Listicle pour "best of", how-to pour "comment", FAQ pour "questions", page produit pour transactionnel | |
| Hiérarchie du contenu | Answer Near the Top | 8.8 | 44,2 % des citations LLM proviennent du premier tiers du contenu (Growth Memo) |
| AI-ready Structure | 8.6 | Headings hiérarchisés, listes, tableaux — pas besoin de chunker, juste rendre la structure visible | |
| Length | 6.7 | La longueur n'est pas un problème en soi, sauf si elle dilue les réponses clés | |
| Qualité des passages | Factually Specific | 8.3 | Chiffres, dates, noms : les articles cités en AIO couvrent 62 % de faits en plus (Surfer SEO) |
| Explicit Phrasing | 8.1 | Formulations directes plutôt qu'évasive ("X est efficace pour Y" plutôt que "certains préfèrent X") | |
| Self-Contained Passages | 8.0 | Chaque paragraphe stratégique doit pouvoir être extrait sans son contexte | |
| Cites Sources | 8.0 | Ajouter des statistiques sourcées augmente les extractions de 33 %, les citations de 41 % (GEO study) | |
| Fraîcheur | Freshness | 7.0 | Variable selon le sujet : critique pour l'actualité, secondaire pour les fondamentaux stables |
Trois points méritent d'être approfondis parce qu'ils sont contre-intuitifs ou particulièrement actionnables.
- La hiérarchie du contenu, d'abord.
Les moteurs IA ne lisent pas votre page entière. Dan Petrovic chez Dejan AI a documenté que Gemini applique un retrieval cap strict par URL, ce qui pénalise mécaniquement les pages où l'essentiel arrive trop tard. La conséquence rédactionnelle est nette : vos réponses denses, vos chiffres clés, vos affirmations différenciantes doivent être placés tôt — pas réservés à une conclusion qui ne sera jamais lue par l'IA.
- La qualité des passages, ensuite.
C'est le terrain où la plupart des contenus échouent sans le savoir. Un passage extractible est un passage qui peut tenir debout seul, avec des affirmations précises et des chiffres explicites. La règle pratique : relire chaque paragraphe stratégique en se demandant "si je l'extrais hors contexte, est-ce qu'il fait sens ?". Si la réponse est non, c'est probablement un passage que l'IA n'extraira pas non plus.
- La fraîcheur, enfin.
Elle compte fortement pour les sujets sensibles au temps (actualité, données chiffrées, évolutions réglementaires) et beaucoup moins pour les sujets stables. La règle pratique : auditez vos contenus stratégiques par cycles courts sur les sujets sensibles, et marquez explicitement les dates de mise à jour pour envoyer le signal côté Google et côté IA.
L'anatomie d'une page "citation-ready" combine ces quatre principes. Le visuel ci-dessous les projette sur un wireframe annoté qui rend la grille immédiatement applicable.
6. Famille 4 — Signaux de confiance et d'entité : l'EEAT en première ligne
Deux facteurs seulement dans cette famille, et ils n'apparaissent pas dans le haut de la grille de Shepard : Brand/Entity Trust est à 6.8 et Entity Consistency à 5.8. Cette discrétion apparente est trompeuse, parce que ces deux facteurs cristallisent un glissement de fond qui mérite un peu plus qu'un examen au score.
Sur les surfaces de recherche classiques, l'EEAT (Experience, Expertise, Authoritativeness, Trust) joue depuis longtemps comme modificateur de ranking : il influence la position d'une page dans une SERP. Sur les surfaces IA, son rôle a sensiblement évolué. L'EEAT y fonctionne désormais comme un filtre de citation : avant même de comparer des pages sur leur pertinence, les moteurs IA semblent privilégier les sources dont la marque, l'auteur ou l'entité sont déjà identifiés et solidement ancrés dans leur représentation du monde. Une étude SE Ranking sur 129 000 domaines a même conclu que la clarté entity de la marque était l'un des meilleurs prédicteurs des citations IA, devant plusieurs indicateurs SEO classiques.
Les signaux qui pèsent côté entité sont assez bien documentés :
- Mentions tierces récurrentes dans des publications reconnues du secteur (un signal plus fort que le backlink seul)
- Profils auteur cohérents avec une présence cross-plateforme (LinkedIn, Google Scholar, GitHub, médias sectoriels)
- Alignement entity sur le web : nommage uniforme de la marque, des produits, des personnes, propriétés
sameAscorrectement renseignées - Présence dans les sources socles que les LLM consultent en priorité : Wikipedia, Wikidata, G2 et Trustpilot pour le B2B, Reddit et Quora pour le grand public
L'effet est différencié selon la plateforme. ChatGPT mise fortement sur le consensus tiers : si Wikipedia, G2, Reddit et plusieurs analystes sectoriels alignent leur positionnement sur vous, votre marque entre dans son référentiel comme un fait. Gemini accorde plus de poids au contenu sous contrôle de marque et aux signaux structurés. Perplexity favorise l'expertise niche sourcée dans des documents spécialisés. Une stratégie efficace touche les trois leviers en parallèle.
Sur le terrain de l'EEAT, j'avais déjà partagé les bonnes pratiques dans un article dédié aux sites thématiques YMYL — la matière s'applique presque ligne pour ligne aux signaux que les moteurs IA reprennent à leur compte. À noter une nuance importante côté citations IA : la profondeur du Experience (vécu de première main) prend plus de poids qu'auparavant, parce que les moteurs cherchent à se prémunir contre la sur-représentation des contenus synthétiques.
En pratique
Trois chantiers concentrent l'essentiel de la valeur :
- Auditer la cohérence entity de votre marque sur le web : naming uniforme, fiches Wikipedia / Wikidata à jour, propriétés
sameAscorrectement renseignées, Knowledge Panel cohérent - Consolider les mentions tierces dans les sources socles consultées par les LLM : G2 et Trustpilot si vous êtes B2B SaaS, Wikipedia si vous y êtes éligible, Reddit et Quora si vous adressez le grand public
- Crédibiliser vos auteurs par des bios riches, des publications cross-domaines, et des profils LinkedIn complets renseignés en
sameAsdu schemaPerson
7. Famille 5 — Les faux amis : rétablir la vérité
Trois facteurs méritent d'être traités à part parce qu'ils mobilisent une part disproportionnée de l'attention de la communauté, sans que les preuves suivent vraiment. Ce n'est pas qu'ils soient inutiles — c'est qu'ils ne sont pas ce qu'on en dit habituellement. Le score que Shepard leur attribue est, à mon sens, plutôt courageux : il refuse la facilité de leur accorder un poids non justifié.
LLMs.txt : score 2/10, et c'est probablement encore trop
Le fichier llms.txt a fait beaucoup parler en 2025. La promesse : un manifeste à la racine du domaine qui indique aux IA quel contenu privilégier. La réalité est plus sobre. À ce jour :
- John Mueller (Google Search Advocate) a déclaré publiquement qu'aucun système IA Google n'utilise
llms.txt - OpenAI, Anthropic et Perplexity n'ont fait aucune annonce sur un usage en production
- Une étude ALLMO de janvier 2026 sur les 50 marques allemandes les plus citées en IA Search a montré qu'aucune ne publiait de
llms.txt. Aucune corrélation détectable - Les analyses de logs serveurs montrent que les crawlers IA majeurs ne fetchent pas le fichier en volume significatif
La position raisonnable n'est pas de "ne rien faire" — implémenter llms.txt coûte une demi-journée et il existe une chance non nulle qu'il devienne utile à terme. Le bet est asymétrique : peu à perdre, optionalité préservée. En revanche, lui accorder une place dans une roadmap stratégique IA en 2026 relève du mésalignement priorité / preuves. C'est un signal de mode, pas un levier mesuré.
Schema markup : un débat éclairé par une étude expérimentale récente
Le score 5.6 que Shepard attribue aux données structurées reflète l'état du débat au moment de la rédaction de son article. Une étude publiée par Ahrefs le 11 mai 2026 — quatre jours après celle de Shepard — apporte un éclairage particulièrement net sur le sujet.
Ahrefs a tracké 1 885 pages qui ont ajouté du JSON-LD entre août 2025 et mars 2026 et les a comparées à 4 000 pages de contrôle via une méthodologie expérimentale rigoureuse (difference-in-differences). Quatre tests indépendants ont produit la même conclusion :
- Google AI Overviews : −4,6 % de citations (effet faible mais statistiquement significatif, sans explication claire)
- Google AI Mode : +2,4 % (statistiquement indistinguable de zéro)
- ChatGPT : +2,2 % (statistiquement indistinguable de zéro)
Autrement dit : ajouter du schema à une page déjà citée par les IA ne produit aucun gain mesurable de citations, quelle que soit la plateforme. Cette donnée renforce une étude antérieure de Search Atlas (décembre 2024) qui ne trouvait déjà aucune corrélation entre couverture schema et taux de citation sur OpenAI, Gemini et Perplexity.
Pour autant, le sujet n'est pas entièrement tranché côté Google et Bing, où les positions officielles divergent du constat empirique :
- Microsoft (Fabrice Canel, SMX Munich, mars 2025) : Bing Copilot utilise effectivement le balisage structuré pour interpréter le contenu
- Google (avril 2025) : les structured data donnent un "avantage" dans les expériences IA-generated search
- Une étude searchVIU citée par Ahrefs précise que sur les cinq principaux moteurs IA (ChatGPT, Claude, Perplexity, Gemini, Google AI Mode), aucun ne semble lire le schema lors du retrieval temps réel — seul le contenu HTML visible est extrait
Deux nuances importantes complètent ce tableau. D'abord, l'étude Ahrefs a porté sur des pages déjà fortement citées — l'effet du schema sur les pages qui n'apparaissent pas encore dans le périmètre de citation des IA reste mal documenté et pourrait jouer un rôle de "ticket d'entrée" pour le crawl et l'extraction. Ensuite, la fameuse GEO study de Princeton et Georgia Tech, souvent invoquée pour défendre le schema, ne teste en réalité pas le balisage structuré mais des stratégies in-content (statistiques, citations sourcées). Cette confusion mérite d'être rectifiée à chaque fois qu'elle apparaît.
La position raisonnable se déduit naturellement : continuer à baliser proprement vos pages — schema reste utile pour les rich results, le SEO classique, et probablement pour les extractions côté Google/Bing qui l'utilisent activement. Mais ne pas en attendre un levier dédié de citations IA sur les LLM purs. Investir 100 heures à enrichir le balisage de tout votre site dans le seul objectif de gagner en visibilité ChatGPT ou Perplexity n'est pas un pari soutenu par les preuves disponibles à date.
Domain Authority : un classique qui ne joue plus directement
Évoqué brièvement en Famille 2, Domain Authority mérite sa place ici parce que la grille de Shepard à 5/10 contredit un automatisme largement répandu. Les études convergent sur une corrélation faible et inconsistante entre DA et citations IA. Cela ne dévalue pas le DA en tant que tel : il reste un indicateur indirect intéressant parce qu'il prédit en partie le ranking organique, qui lui-même influence encore les citations. Mais en levier dédié de stratégie IA, le DA n'est pas là où on l'attendait. Les signaux d'entité (cf. Famille 4) priment.
8. Synthèse : quatre chantiers pour piloter sa visibilité IA
Le travail de Shepard reste précieux. Il pose une grille de référence pondérée là où la communauté n'avait que des frameworks isolés, et son honnêteté méthodologique mérite d'être saluée. Ce qu'il offre, c'est une photo bien cadrée d'un sujet en constante évolution.
De la lecture critique de cette grille, trois constats principaux ressortent.
D'abord, le pont SEO / GEO se déplace plus qu'il ne s'effondre. Ranker top 10 reste un avantage mesurable, mais devient insuffisant : la chute de la corrélation de 76 % à 17 % en sept mois est trop nette pour être ignorée. Le fan-out installe une nouvelle logique de couverture où la pertinence sur les sous-intents pèse autant que la position sur la requête principale. Penser sa stratégie de contenu en clusters thématiques devient la norme.
Ensuite, les signaux d'entité prennent une importance que les indicateurs SEO classiques ne capturent pas. Le Domain Authority décroche, Brand Trust et Entity Consistency montent en pertinence stratégique sans monter en score chez Shepard. L'EEAT bascule du statut de modificateur de ranking à celui de filtre de citation. C'est probablement le glissement le plus structurant pour 2026.
Enfin, certains paris technologiques sont à arbitrer froidement. LLMs.txt reste un investissement asymétrique à faible coût mais sans preuve à date. Schema markup garde une valeur SEO incontestée mais ne fait pas bouger les citations IA sur les LLM purs, comme le confirme l'étude expérimentale Ahrefs de mai 2026. Continuer à les soigner, oui ; en faire des piliers de stratégie IA, non.
Les quatre chantiers prioritaires
Pour traduire ces lectures en plan d'action, quatre chantiers concentrent l'essentiel de la valeur :
- Auditer votre accessibilité aux moteurs IA. Vérifier votre
robots.txt, vos preview controls, votre rendu HTML, et surtout votre configuration WAF / Cloudflare. C'est le chantier le moins coûteux et le plus immédiatement rentable. - Penser votre stratégie de contenu en clusters de sous-intents. Identifier les fan-outs probables de vos requêtes cibles, couvrir chaque facette par une page dédiée, densifier le maillage interne entre ces pages. C'est le chantier qui demande le plus de méthode, et c'est aussi celui qui a le plus de potentiel à 12 mois.
- Construire des pages citation-ready. Placer les réponses denses en haut, écrire des passages auto-suffisants, ancrer les affirmations dans des chiffres et des sources. C'est un chantier de standards éditoriaux à diffuser dans vos équipes de rédaction.
- Consolider vos signaux d'entité et de marque. Audit entity cross-web, alignement des bios auteurs, présence dans les sources socles (Wikipedia, G2, Trustpilot, Reddit selon votre marché), enrichissement progressif des mentions tierces. C'est le chantier le plus long et le plus différenciant.