Visibilité IA : ce que les outils mesurent vraiment
Trois cadres, trois outils, des limites communes. Ce que la mesure de la visibilité IA peut vraiment livrer en 2026, et ce qu'elle laisse aux équipes à construire.
Mesurer sa visibilité dans les IA, en 2026, est un exercice plus difficile qu'il n'y parait. Les outils existent, les cadres méthodologiques se sont structurés, le marché s'organise autour de quelques acteurs. Pourtant, quand on prend le temps de regarder ce que tout cela mesure vraiment, on tombe sur trois constats : la donnée bouge d'un jour à l'autre sans qu'on sache toujours pourquoi, les outils mesurent des données qui ne se recouvrent pas, et une partie significative de ce qu'il faudrait suivre ne se trouve dans aucune solution existante sur le marché.
Cet article propose une lecture structurée du sujet pour un lecteur qui doit piloter, justifier des budgets ou évaluer un outil : trois cadres méthodologiques qui tiennent, six métriques nouvelles qui montent à mesure que l'AI Search bascule vers un fonctionnement agentique, trois outils de référence présentés factuellement, et plusieurs "angles morts" qui mettent en avant la limite des méthodes de suivi actuelles.
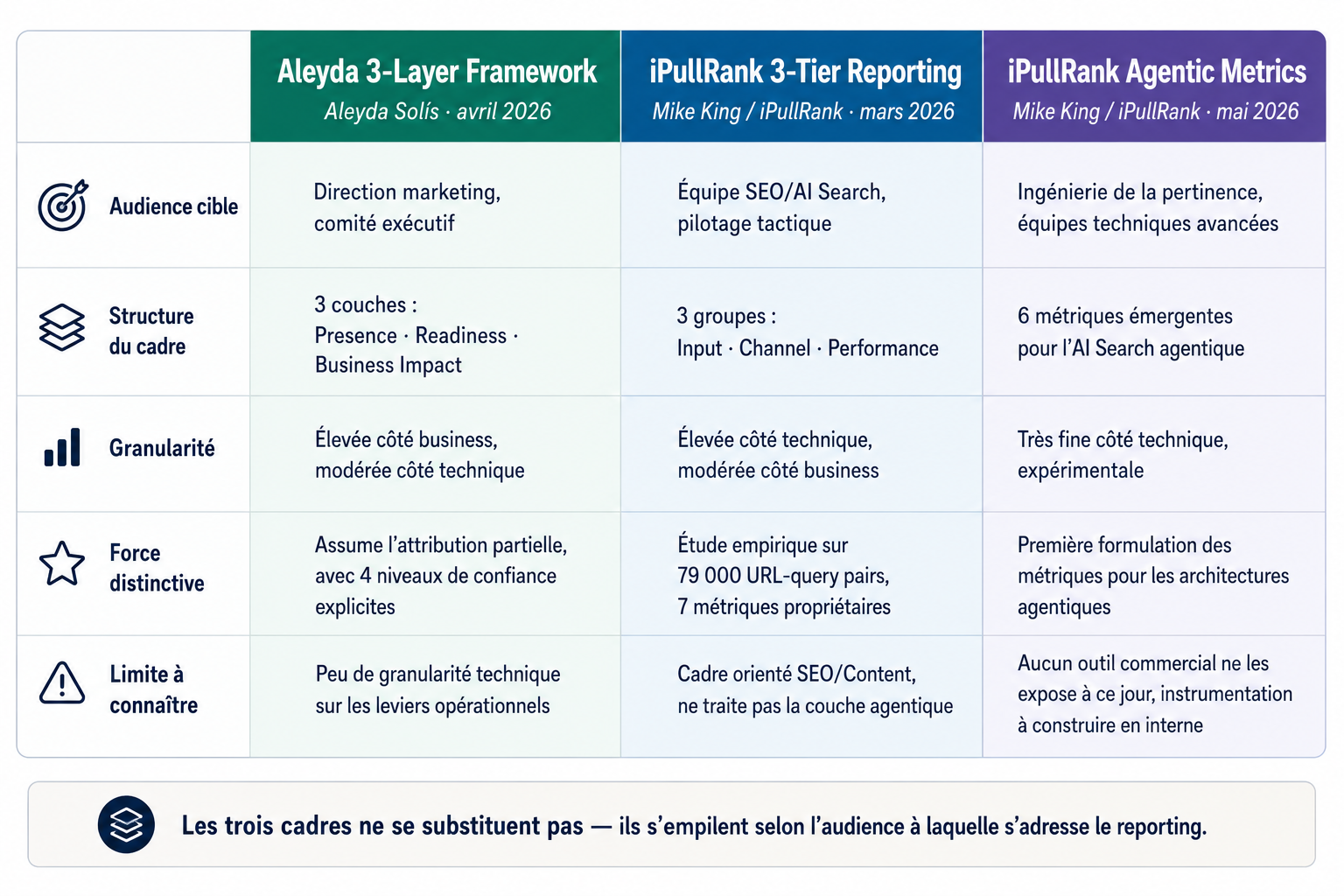
- Trois cadres méthodologiques qui se complètent : Aleyda 3-Layer Framework (presence / readiness / business impact), iPullRank 3-Tier Reporting Model (input / channel / performance), et iPullRank Agentic Metrics, les six métriques issues de Beyond RAG (mai 2026). Aucun ne s'oppose aux autres ; tous s'articulent selon l'audience à laquelle on adresse le reporting.
- Les six métriques agentic (sub-query coverage, retrieval-to-citation ratio, reflection survival rate, bridge-entity centrality, tool-call inclusion, distillation stage-failure rate) constituent la nouveauté forte de 2026. Elles répondent au passage du RAG single-shot à un fonctionnement agentique, dans lequel le citation tracking traditionnel ne suffit plus à objectiver la visibilité réelle.
- Trois limites structurelles interdisent de penser le suivi visibilité IA comme une évolution du rank tracking : le non-déterminisme des LLMs (sorties variables à prompt identique), la personnalisation invisible (contexte utilisateur, embedding personnel, mémoire ambient), l'absence de search volume agrégé (pas d'équivalent du keyword volume).
- Trois outils dominent le marché en 2026 avec trois approches distinctes : Profound (data provider), Peec AI (tracker pur orienté product), Otterly (méthodologie d'expérimentation publique). Aucun ne mesure aujourd'hui le triple cadre dans son entier, ni n'embarque les six métriques agentic sur lesquelles nous allons revenir.
- La posture de pilotage qui tient : mesurer la dynamique plutôt que la position absolue, croiser les sources plutôt que dépendre d'un outil unique, lire le suivi visibilité IA comme un signal directionnel plutôt que comme un KPI absolu. Et accepter que la part de bruit reste élevée — c'est la nature du sujet, pas un défaut des outils.
Pourquoi mesurer la visibilité IA ne ressemble pas au rank tracking
L'article précédent posait la distinction qui sépare la récupération ancrée (grounded retrieval) de la génération probabiliste (probabilistic generation) — deux mécanismes très différents qui s'enchaînent quand une IA répond à votre question. La récupération va chercher dans un index, elle reste mesurable avec les fondamentaux SEO. La génération produit une sortie de tokens en s'appuyant sur des distributions de probabilités, elle n'est pas reproductible. La mesure de la visibilité IA repose entièrement sur cette asymétrie : on essaie d'objectiver un comportement de sortie qui n'a pas la stabilité dont on a hérité du rank tracking.
Trois limites structurelles méritent d'être posées clairement. Pas comme un disclaimer, mais comme la matière même du problème.
Le non-déterminisme
Plusieurs paramètres internes pilotent la génération de la réponse. La température, qui contrôle le degré de variation autorisée dans le choix des mots. Le seed — la valeur numérique qui initialise le tirage probabiliste interne — rarement exposé aux outils tiers, ce qui empêche de fixer une sortie reproductible. La version exacte du modèle au moment de l'inférence, c'est-à-dire au moment où il génère votre réponse, qui peut changer d'une requête à l'autre sans préavis. Et les fluctuations du contexte au sein d'une session. Autant de variables qui produisent une variance comportementale qui n'est pas du bruit de mesure, mais une caractéristique de fonctionnement.
La personnalisation invisible
Une part substantielle de ce qu'un utilisateur voit dans une réponse IA dépend d'éléments que personne d'autre ne voit. Une mémoire d'arrière-plan stockée dans son profil — Google a breveté le mécanisme dès mars 2024, avant même que ChatGPT Memory n'existe. Un embedding utilisateur, qui décrit ses centres d'intérêt dans un modèle de représentation. Le contexte conversationnel des sessions précédentes. La géolocalisation. La langue de l'interface.
Aucun outil tiers n'a accès à ces signaux. Quand un tracker remonte "votre marque apparaît dans 35 % des réponses sur cette requête", il rapporte 35 % d'apparition dans une simulation neutre du profil utilisateur, qui n'existe en pratique pour personne. La mesure ne ment pas, mais elle mesure une situation qui n'existe pas.
L'absence de volumétrie agrégée
Sur le rank tracking classique, le volume de recherche par mot-clé est une donnée publique exploitable. On sait combien de fois "assurance habitation" est requêté dans Google chaque mois. En AI Search, il n'existe aucun équivalent. Ni les éditeurs d'outils, ni les plateformes elles-mêmes ne publient de volumétrie agrégée des prompts. Personne ne sait combien de fois votre catégorie est vraiment interrogée dans ChatGPT, Perplexity, Gemini ou Claude, et cette donnée n'est pas près d'être commercialisée comme l'est le volume de mots-clés Google.
Conséquence : tous les outils de tracking échantillonnent sur la base d'une bibliothèque qu'ils construisent, pas d'une volumétrie qu'ils observent. Ils maintiennent une bibliothèque de prompts (quelques centaines à quelques milliers de requêtes représentatives d'un marché) et ils mesurent votre visibilité sur cette bibliothèque. La bibliothèque est un artefact, pas une réalité.
Le piège du citation tracking : ce que dit l'étude Oumi/NYT
Une étude publiée en avril 2026 illustre l'angle mort le plus problématique. Le New York Times a commandé à la startup Oumi une analyse de la précision des AI Overviews de Google. Méthodologie : 4 326 requêtes testées sur le benchmark SimpleQA (un standard sectoriel conçu par OpenAI), en deux vagues — octobre 2025 sur Gemini 2, février 2026 sur Gemini 3.
Les résultats : Gemini 3 produit des AI Overviews correctes à 91 % (contre 85 % avec Gemini 2). Mais sur ces réponses correctes, 56 % sont qualifiées d'ungrounded — c'est-à-dire qu'elles citent des sources qui, à la vérification, ne supportent pas réellement l'information donnée. La proportion était de 37 % avec Gemini 2 ; elle a presque doublé avec Gemini 3.
Autrement dit : quand votre marque apparaît dans une AI Overview avec un lien vers votre site, il y a plus d'une chance sur deux pour que la phrase autour du lien n'ait pas de fondement vérifiable dans votre page. Le tracker comptabilise la citation comme un signal positif. La réalité est ailleurs.
Le citation tracking traditionnel — celui que les outils du marché vendent comme métrique centrale — n'a pas de réponse à cette dérive. Il compte des liens, pas des liens fondés. Il agrège du signal et du bruit dans la même colonne.
Trois cadres méthodologiques qui structurent la mesure en 2026
Une fois les limites posées, la question devient pratique : comment construire une lecture fiable de sa visibilité IA, malgré la variance, la personnalisation et le bruit ? Trois cadres méthodologiques se sont consolidés en 2026 pour répondre à cette question. Aucun ne prétend résoudre ces limites structurelles — chacun propose juste une manière de s'organiser autour d'elles. Ils ne s'opposent pas. Ils correspondent à trois lectures complémentaires de la même réalité, qui se présentent comme trois couches d'analyse pour trois audiences différentes : la direction business, l'équipe opérationnelle, et l'ingénierie de la pertinence.
Le 3-Layer Framework : présence, readiness, impact business
Le premier cadre est celui d'Aleyda Solís, publié en avril 2026 sous le titre A 3 Layer Framework to Measure AI Presence, Readiness and Business Impact. C'est le plus accessible des trois pour parler à une direction marketing ou à un comité exécutif, parce qu'il structure la mesure autour de questions business pures.
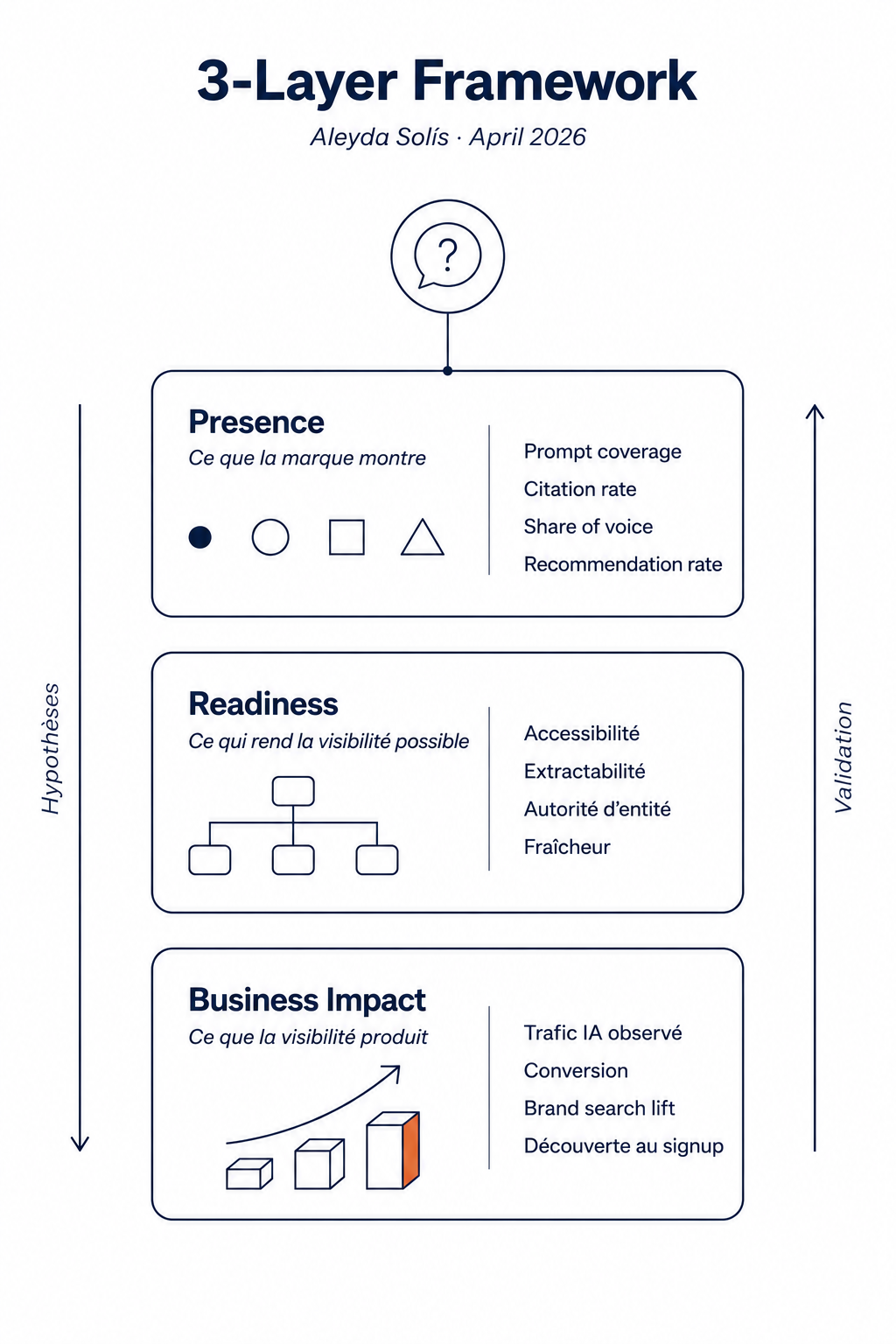
Trois couches connectées, avec un rôle distinct pour chacune.
Layer 1 — Presence mesure si et comment votre marque apparaît dans les réponses IA. Cinq KPI principaux : le prompt coverage (sur quelle proportion d'une catégorie de prompts représentatifs vous apparaissez), le recommendation rate (parmi ces apparitions, combien de fois vous êtes recommandé explicitement), le linked citation rate (combien de fois le lien vers votre site est cliquable), le comparative win rate (sur les prompts comparatifs, combien de fois vous êtes préféré), et la representation accuracy (parmi vos mentions, combien sont correctement positionnées sur votre proposition de valeur). Tracé sur une dizaine de plateformes, ce groupe de KPI dessine une cartographie de surface.
Layer 2 — Readiness diagnostique pourquoi la visibilité se présente ainsi. Le cadre identifie dix caractéristiques structurelles que les marques gagnantes en AI Search partagent : accessibilité, extractabilité, fraîcheur, autorité d'entité, présence dans les sources tierces de confiance, et ainsi de suite. Un trou en Presence devient une hypothèse Readiness à tester : si votre prompt coverage est bas dans une catégorie, le diagnostic se déplace côté infrastructure.
Layer 3 — Business Impact mesure si la visibilité crée de la valeur commerciale. C'est l'apport le plus distinctif du framework : Aleyda Solís y assume l'attribution partielle, plutôt que de prétendre la résoudre. Quatre niveaux de confiance à séparer rigoureusement dans le reporting :
- Observé (Observed) : métriques natives avec referrer ou UTM. Confiance haute, couverture faible.
- Proxy propriétaire (Proxy own) : signaux internes [...]
- Proxy externe (Proxy third-party) : données externes [...]
- Modélisé (Modelled) : estimations issues d'hypothèses [...]
Le principe qui rend le cadre opérationnel : chaque couche passe une hypothèse à la suivante. Un trou de Presence devient un chantier de Readiness, qui devient une action dont l'effet est mesuré via le Business Impact. La formule d'Aleyda Solís qui résume la posture : "Measured AI referral traffic is the floor, not the ceiling, of AI's contribution."
Le 3-Tier Reporting Model : input, channel, performance
Le deuxième cadre vient d'iPullRank, posé par Mike King et son équipe dans l'article Beyond Rankings publié en mars 2026. La granularité y est plus fine que dans le 3-Layer, parce que le cadre est conçu pour piloter une équipe SEO/AI Search au niveau tactique. Trois groupes de métriques couvrent le customer journey complet.
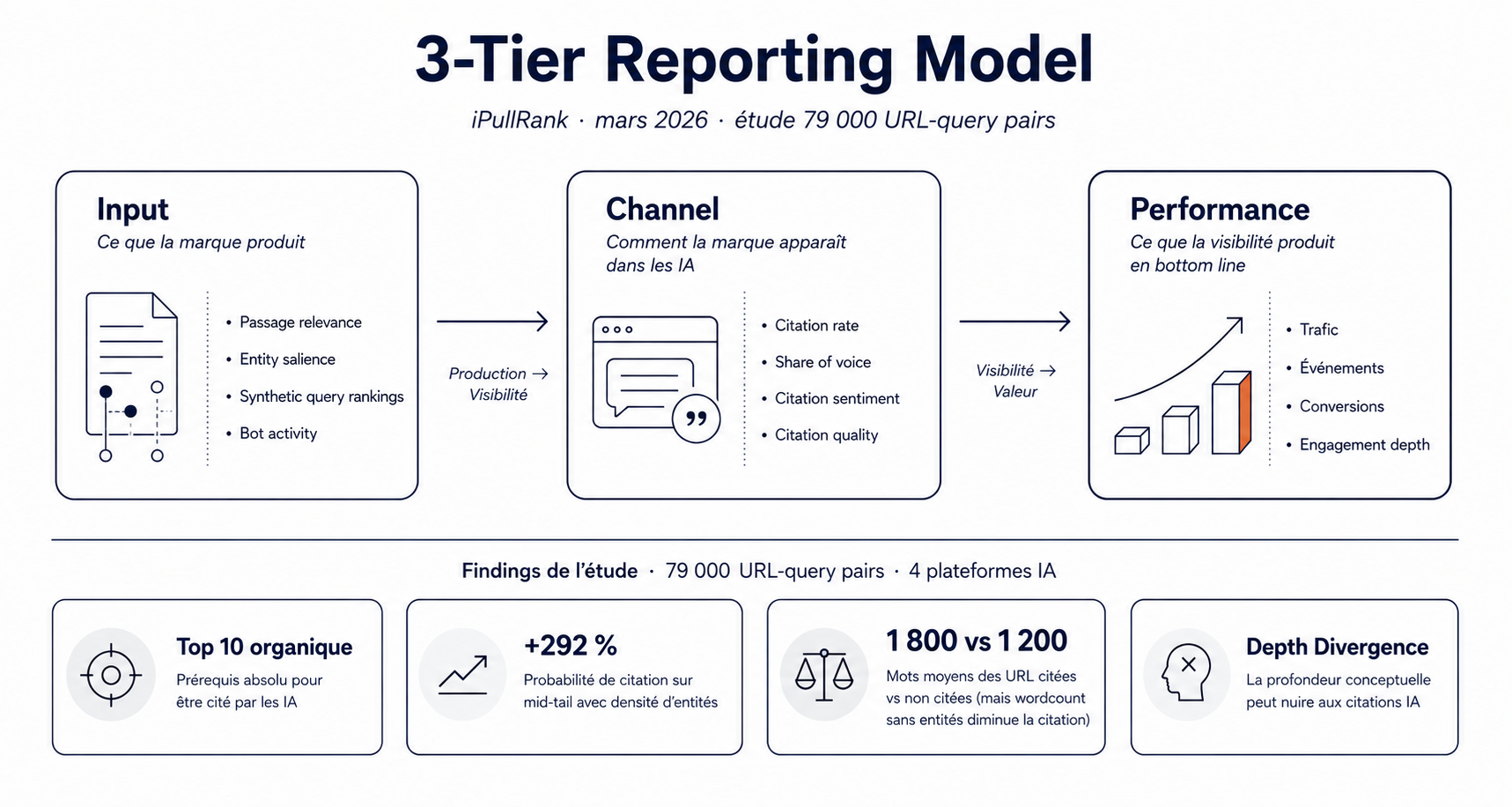
Input Metrics mesurent la substance du contenu produit, côté IA. Quel est l'alignement sémantique entre vos pages et les requêtes qui comptent ? Quelle est la pertinence des passages quand un retriever les évalue ? La fraîcheur du contenu, l'activité des bots sur le site, le ranking sur les synthetic queries — ces sous-requêtes que les agents génèrent à partir d'une question initiale. C'est la couche qui se rapproche le plus du SEO technique traditionnel, mais traduite en signaux que les LLMs lisent réellement.
Channel Metrics mesurent la visibilité de la marque, ce qu'iPullRank appelle la "nouvelle SEO" : citations, share of voice, citation rate, citation quality, et — apport notable — citation sentiment. Cette dernière métrique est l'une des plus structurantes : ce n'est plus seulement "êtes-vous cité", mais "comment êtes-vous cité". Une citation positive et une citation neutre n'ont pas la même valeur business.
Performance Metrics mesurent ce que la visibilité produit : trafic, événements, conversions, profondeur d'engagement. Le cadre traite l'AI Search à la fois comme un canal de marque et comme un canal de performance.
iPullRank a documenté ce cadre par une étude originale sur 79 000 URL-requête analysées sur quatre plateformes IA (ChatGPT, Claude, Perplexity, Google). Quatre enseignements opérationnels en ressortent. D'abord, le top 10 organique Google reste un prérequis absolu pour être cité par les IA, avec une baisse marquée au-delà. Ensuite, les mid-tail queries optimisées voient +292 % de citation probability. Le troisième est plus nuancé : les URL citées font 1 800 mots en moyenne contre 1 200 pour les non-citées, mais ajouter du nombre de mots sans augmenter la densité d'entités diminue la probabilité de citation. Le quatrième est le plus contre-intuitif : la Conceptual Depth, traditionnellement valorisée en SEO, peut nuire aux citations IA, qui cherchent la réponse la plus directe possible. C'est ce qu'iPullRank appelle la Depth Divergence.
Sept métriques propriétaires opérationnalisent le cadre : Cosine Similarity, Comprehensive Coverage Index, Strategic Entity Richness, Explanatory Efficiency Index, Conceptual Depth Score, Information Gain Score, Entity Density. Chacune a sa définition technique et son "why it matters" en termes de comportement LLM. L'article complémentaire Clicks to Citations (avril 2026) y ajoute une dimension persona-driven : les KPI doivent être segmentés par persona, parce que des audiences différentes utilisent des vocabulaires différents, et la visibilité par segment compte davantage que la moyenne globale.
Les six métriques agentic : le nouveau cadre qui change la donne
Le troisième cadre est le plus récent et le plus structurant. Mike King l'a posé en mai 2026 dans Beyond RAG: Why Every AI Search Platform Is Now Agentic. Le diagnostic est direct : le RAG single-shot — une requête, une récupération, une réponse — n'est plus l'architecture par défaut. Toutes les plateformes IA majeures (Google AI Mode, ChatGPT Deep Research, Perplexity Pro, Claude, Gemini Deep Research) ont basculé sur l'Agentic RAG, une architecture définie par quatre propriétés structurelles : Planning (le plan de recherche est généré avant toute récupération), Tool Use (la récupération n'est qu'un outil parmi d'autres), Iteration (l'agent récupère, lit, récupère à nouveau), Reflection (le système grade son propre brouillon avant de produire la sortie finale).
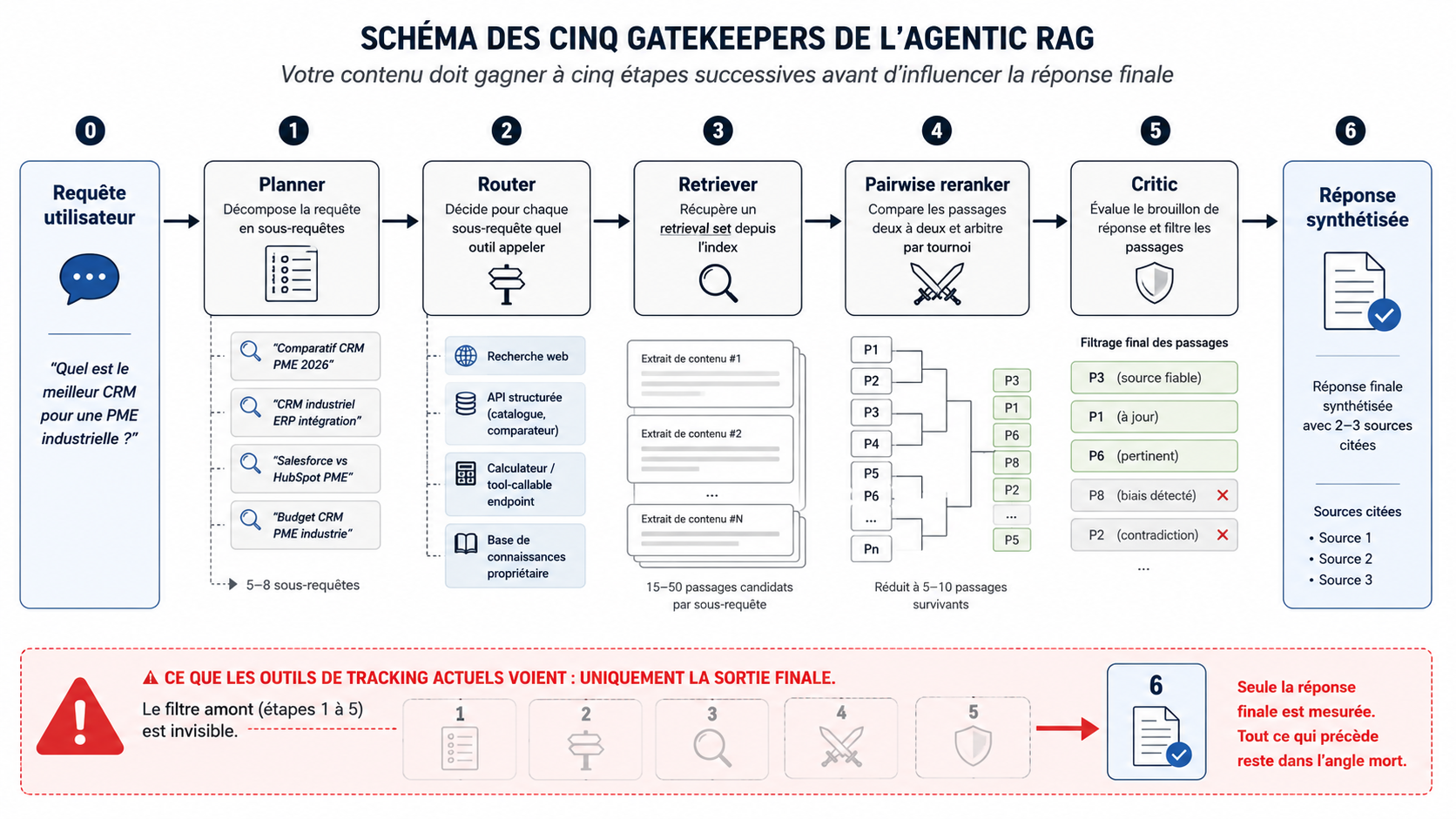
Concrètement : une seule requête utilisateur est décomposée en 5 à 20 sous-requêtes. Votre contenu doit gagner à cinq étapes successives — le planner qui décompose la requête, le router qui choisit les outils, le retriever qui récupère les passages candidats, le pairwise reranker qui les compare et le critic qui les filtre une dernière fois. Chaque gatekeeper en amont du résultat final est invisible au tracker classique. C'est ce qui produit le diagnostic central de Mike King : le citation tracking traditionnel sous-estime votre empreinte réelle par un facteur de 3 à 10× dans les systèmes agentiques. Si vous apparaissez dans quatre des douze sous requêtes mais que vous n'êtes cité qu'une seule fois dans la réponse finale, le citation tracking manque 75 % de votre impact réel.
Les six métriques posées par Mike King ne se substituent pas aux métriques classiques — elles s'ajoutent à elles pour couvrir les angles morts du pipeline agentique. Pour les comprendre, le plus simple est de les rattacher au pipeline qu'on vient de décrire : quatre métriques se placent à des étapes précises du filtre (planner, router, retriever/reranker, critic), et deux fonctionnent transversalement (positionnement structurel dans le graphe et diagnostic global).
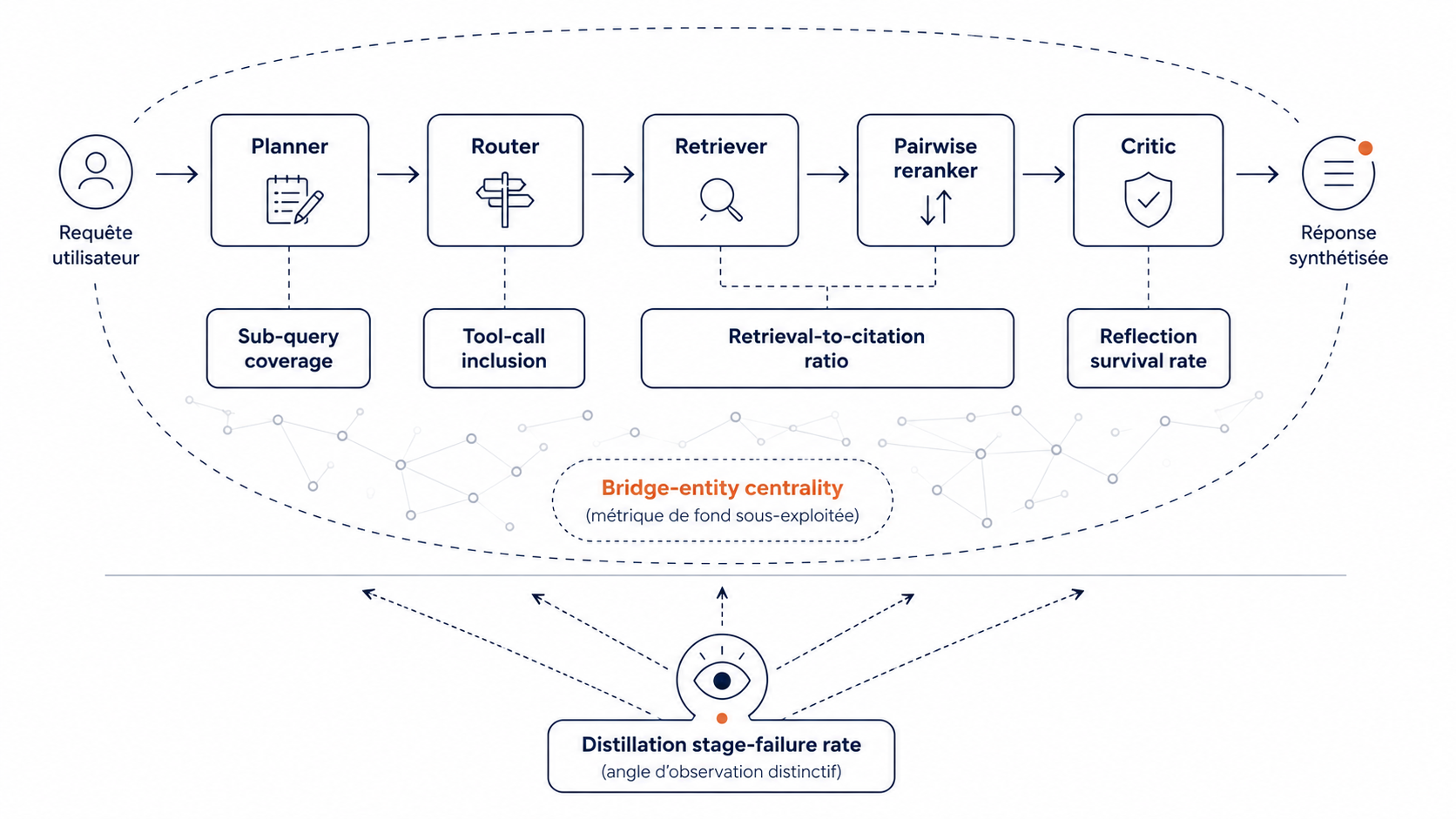
Les quatre métriques de gatekeeper
Sub-query coverage — au niveau du planner. Quelle proportion du plan de recherche vous concerne ? Admettons qu'une requête utilisateur "meilleur CRM pour PME industrielle" est décomposée par le planner en dix sous-requêtes. Si votre contenu apparaît dans quatre d'entre elles, votre sub-query coverage est de 40 %. La métrique révèle quelque chose d'invisible aux trackers classiques : vous pouvez être absent de la requête principale et présent sur ses sub-query. L'action induite est de couvrir la diversité sémantique de votre catégorie, pas seulement les requêtes principales.
Tool-call inclusion — au niveau du router. Un agent ne se contente pas de lire des passages : il peut aussi appeler des outils pendant qu'il construit sa réponse. Un calculateur de tarif, une API de stock produit, un comparateur, un service de réservation. Si votre marque expose des outils accessibles à ces appels — un calculateur public, une API ouverte, un point d'accès via le protocole MCP — l'agent peut les solliciter pour produire une réponse précise. Cette métrique mesure à quelle fréquence vos outils sont effectivement appelés quand une sous-requête le justifierait. C'est une dimension nouvelle de la visibilité IA : vous n'êtes pas cité, vous êtes utilisé.
Retrieval-to-citation ratio — sur les sous-requêtes où votre contenu fait partie des passages récupérés, à quelle fréquence parvient-il jusqu'à la citation finale ? Si votre contenu est récupéré 10 fois sur cent, votre ratio est de 10 %. Un ratio faible signale que vous êtes bien indexé mais que vous perdez systématiquement au niveau du pairwise rerank. C'est probablement la métrique la plus actionnable pour une équipe content, parce qu'elle pointe directement vers la qualité intrinsèque du passage.
Reflection survival rate — au niveau du critic. Votre contenu parvient-il au filtre du critic ? Le critic, dernier gatekeeper avant la sortie, évalue le brouillon de réponse et retire les passages qui présentent des signaux d'alerte : fraîcheur insuffisante, contradiction interne, signaux de fiabilité faibles, biais détecté. Si votre contenu apparaît dans cinquante brouillons et que le critic en retire huit, votre reflection survival rate est de 84 %. C'est une métrique de qualité éditoriale au sens strict — fraîcheur, alignement avec les sources d'autorité et des signaux EEAT.
Les deux métriques transversales
Bridge-entity centrality — au niveau du graphe sémantique. Êtes-vous positionné comme le lien canonique entre les entités clés ? Cette métrique ne s'ancre pas à une étape du pipeline, elle mesure une position dans le graphe thématique global. Quand l'agent cherche les relations entre deux entités — par exemple "CRM industriel" et "intégration ERP" —, il privilégie les sources qui font canoniquement le pont entre les deux. Si vous êtes cette source de ce pont, vous êtes cité dans des réponses où l'utilisateur n'a jamais tapé votre nom. C'est probablement la métrique la plus sous-exploitée à ce jour. Elle ne se travaille pas par optimisation de page — elle se construit par positionnement thématique, contenus de fond qui croisent deux entités, mentions tierces qui valident le pont.
Distillation stage-failure rate — depuis un agent local. À quelle étape du pipeline perdez-vous le plus ? Cette dernière métrique se distingue de toutes les autres : elle ne se mesure pas en interrogeant les plateformes IA, elle se mesure depuis un agent local que vous opérez en parallèle, qui reproduit l'architecture en cinq étapes et observe où votre contenu est retiré dans la majorité des cas. Si vous perdez 60 % au reranker, 25 % au critic, 15 % au retriever, vous savez où agir en priorité. C'est la seule métrique strictement diagnostique du lot — les autres mesurent l'effet, celle-ci pointe la cause. Elle suppose une technique à part, c'est le levier qui transforme la mesure en pilotage.
Ce que cela change
Les six métriques redessinent ce qu'il faudrait suivre pour avoir une lecture fidèle de la visibilité réelle dans l'AI Search 2026. Aucune n'est dans un outil commercial à ce jour. Mais leur formulation opérationnelle est désormais publique, le repository iPullRank donne une architecture de référence, et la communauté GEO commence à se les approprier. À court terme, c'est probablement la principale différenciation qui se dessine entre les équipes les plus avancées et les autres : non pas l'outil de tracking choisi, mais la capacité à mettre en place un suivi que les plateformes existantes ne permettent pas.
Aucune de ces six métriques n'est aujourd'hui dans un outil commercial. Pour l'instant, on retient qu'elles existent, qu'elles sont opérationnellement définies, et qu'elles redessinent ce qu'il faudrait suivre pour avoir une lecture fidèle de la visibilité réelle dans l'AI Search 2026.
L'articulation des trois cadres
Les trois cadres ne se substituent pas. Ils se complètent entre eux. Aleyda 3-Layer donne la lecture business pour le reporting exécutif. iPullRank 3-Tier donne la lecture opérationnelle pour le pilotage tactique. Les six métriques agentic donnent la lecture technique émergente pour l'ingénierie de la pertinence. Le bon usage, en pratique, consiste à les articuler selon l'audience : trois niveaux de reporting pour trois questions différentes — où en est-on, pourquoi, comment l'améliorer.
Le panorama du marché : trois outils, trois approches
Le marché du suivi de visibilité IA s'est structuré en deux ans autour de quelques acteurs. Trois d'entre eux dominent le marché en 2026, chacun avec une approche méthodologique distincte. Aucun ne se substitue à un autre : ils répondent à des questions différentes, et il est fréquent que des équipes expertes en combinent deux selon les usages. Plutôt qu'un comparatif d'achat — qui daterait dans trois mois — on les présente ici sur quatre dimensions stables : positionnement et fonctionnalités, méthodologie de capture, expertise et production éditoriale. Une cinquième dimension, transversale, examine où chacun se loge dans le triple cadre méthodologique posé précédemment.
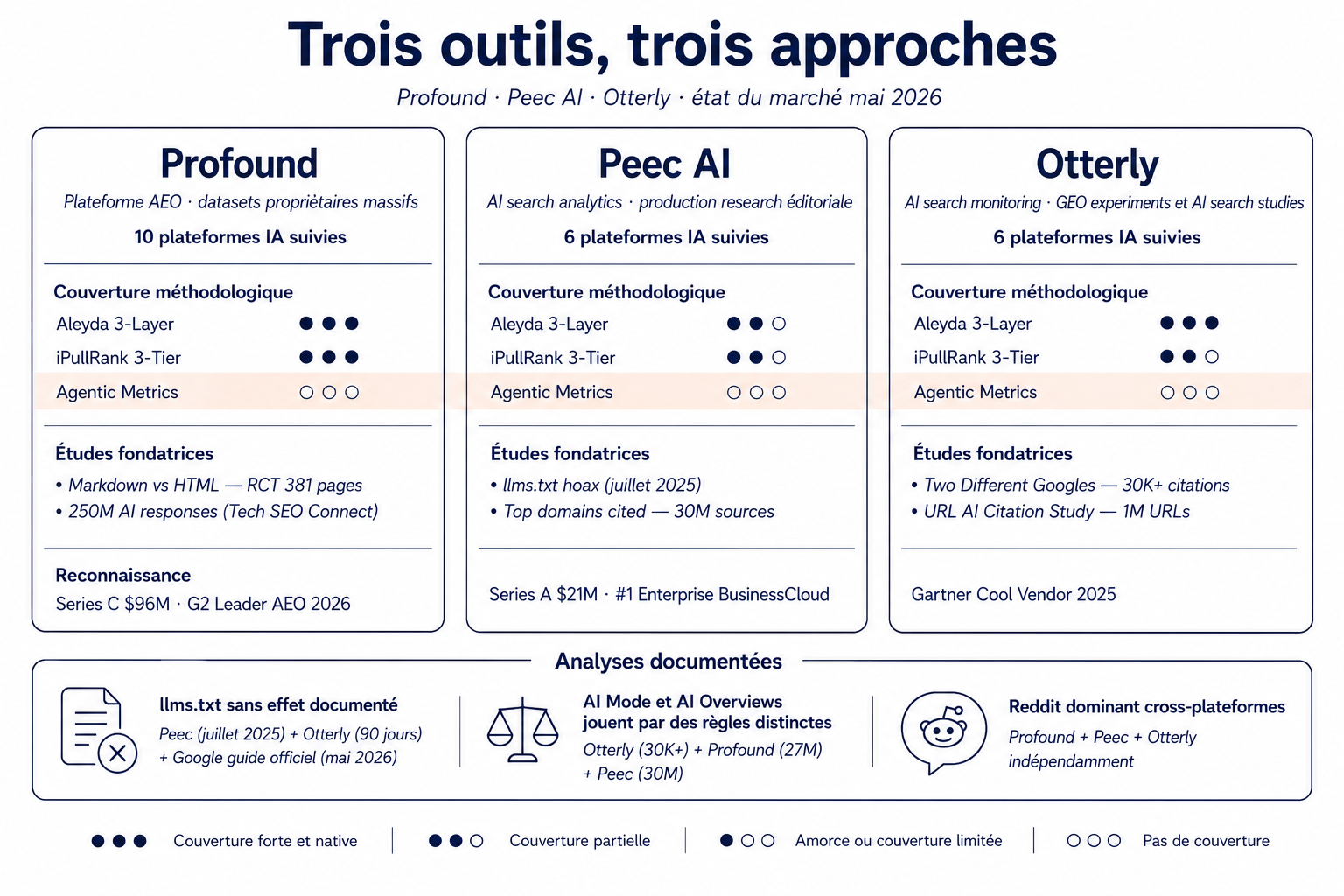
Profound : volume d'études et discipline méthodologique
Profound se positionne comme la plateforme de référence pour l'Answer Engine Optimization, avec une Series C $96M levée en février 2026 (valorisation 1 milliard de dollars) qui en fait l'acteur le mieux financé du secteur. La proposition produit s'organise autour d'Answer Engine Insights (tracking de visibilité, share of voice, sentiment, sources citées, classement face aux concurrents), Agent Analytics (mesure du trafic IA réel sur le site au niveau infrastructure) et Prompt Volumes (estimation des volumétries de prompts par marché). Couverture annoncée : dix moteurs de réponse, plus de trente langues, suivi quotidien.
La méthodologie distinctive de Profound : la capture des réponses IA se fait directement depuis le navigateur plutôt que via l'API. La promesse est d'éviter les écarts de comportement entre les versions API et les versions consommateur des modèles.
Mais ce qui distingue le mieux Profound, c'est le volume et la rigueur de sa production research. Le dataset cumulé dépasse les 3,25 milliards de citations IA en 2025-2026, et la plateforme publie régulièrement des études fondatrices nommées :
- Markdown vs HTML — RCT 381 pages (Brandon Punturo, février 2026). Première étude contrôlée randomisée publique sur l'effet du Markdown servi aux crawlers IA. Sur 6 sites, 381 pages réparties aléatoirement (HTML pour le control, Markdown pour le treatment), mesure du trafic bot sur 3 semaines. Résultat : pas d'effet statistiquement significatif. Profound publie une étude qui invalide une hypothèse populaire potentiellement favorable à son propre produit.
- 250M AI responses Tech SEO Connect (Josh Blyskal, décembre 2025). Analyse de 250 millions de réponses IA à travers 8 answer engines. Pose cinq diagnostics structurants pour le marché AI Search : 39 % seulement d'overlap ChatGPT/Google SERP, citation flattening (les LLMs distribuent l'attention plus uniformément que les humains sur les positions 1-10), 2,4 sub-queries moyennes par prompt en fan-out, indexation Google comme prérequis sans être suffisante.

- 27M Citation Categories (Brandon Punturo, janvier 2026). Classification de 27 millions de citations en 8 catégories de sources à travers 7 plateformes IA. Documente la diversité des sources et la divergence par plateforme (Perplexity 19 % social vs ChatGPT 5 %).
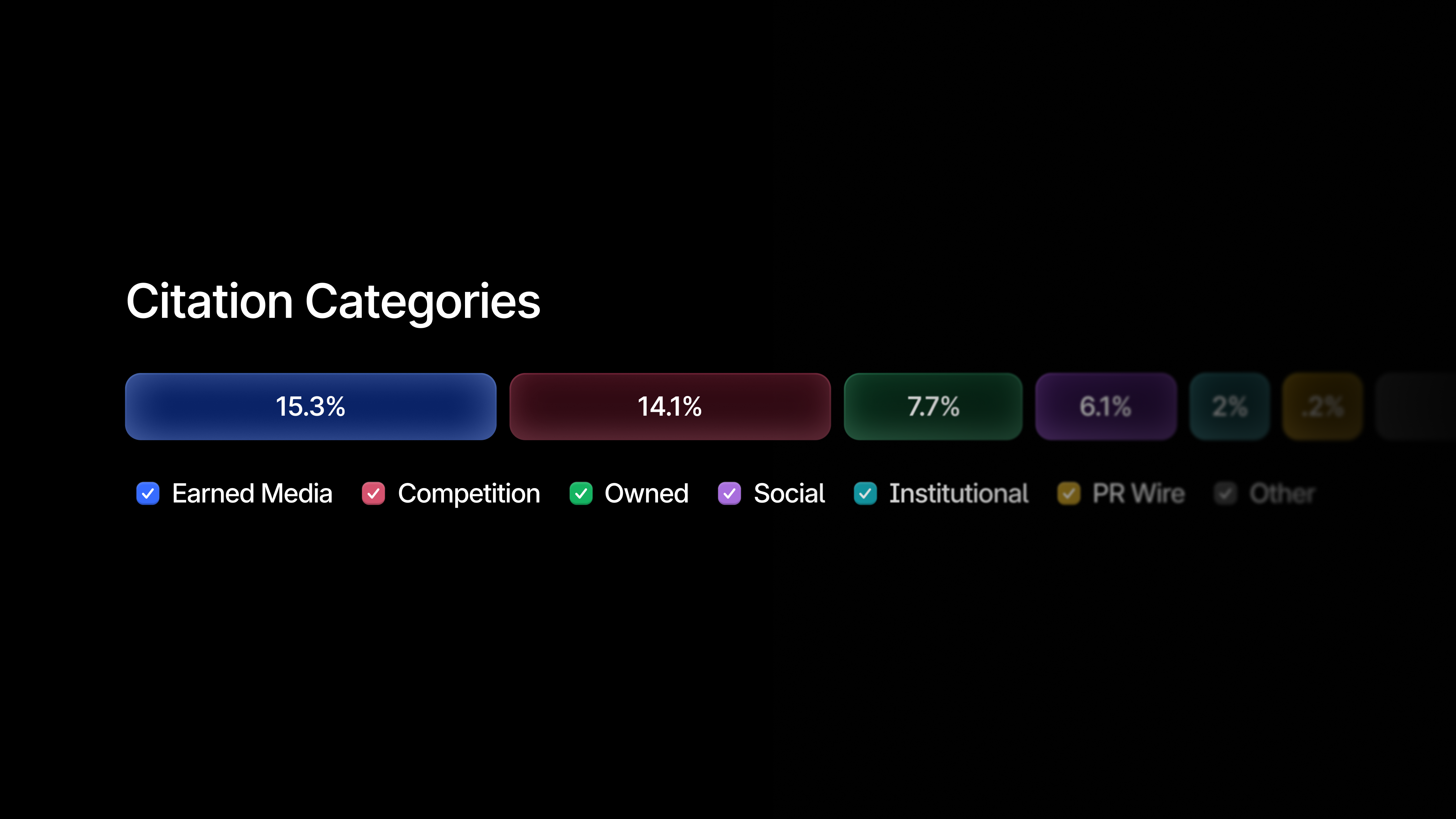
Dans le triple cadre méthodologique, Profound couvre fortement la couche Presence d'Aleyda et apporte une dimension Business Impact via Agent Analytics qui mesure le trafic IA réel. Côté iPullRank, principalement des Channel Metrics, avec une amorce d'Input Metrics via les recommandations de contenu. Les six métriques agentic ne sont pas exposées à ce jour.
Peec AI : l'approche tracker pur, orienté produit
Peec AI se présente comme une plateforme d'AI search analytics conçue pour les équipes marketing, avec une Series A de 21 millions de dollars levée en novembre 2025 et plus de 1 300 marques et agences onboardées depuis le lancement en février 2025. Basée à Berlin, la plateforme assume un positionnement européen distinct des acteurs US. Couverture annoncée : six plateformes (ChatGPT, Perplexity, Gemini, Microsoft Copilot, Google AI Mode, Google AI Overviews), multi-pays, plus de 115 langues.
La méthodologie distinctive : une extraction depuis l'interface utilisateur (UI scraping) plutôt que via l'API, avec l'argument d'éviter les écarts API/UI. La plateforme met en avant la classification des sources citées en cinq catégories (éditorial, UGC, concurrent, référence, informationnel) pour diagnostiquer l'origine de la visibilité, ainsi qu'une détection regex et un prompt clustering pour les régimes de monitoring profonds.
Côté production research, Peec AI développe une matière éditoriale soutenue avec une dimension critique assumée :
- llms.txt hoax (Malte Landwehr, juillet 2025). Article éditorial fondateur qui falsifie l'engouement sectoriel pour le protocole llms.txt — proposé par Jeremy Howard en septembre 2024 et adopté par 600+ sites mi-2025. Aucun answer engine n'a annoncé supporter le protocole, et John Mueller (Google Search Advocate) confirme dans le Search Console Help Community que les AI services ne le vérifient même pas dans les server logs. Article qui a structuré la critique sectorielle sur les pratiques GEO sans preuve.

- Top domains cited — 30M sources (Tomek Rudzki, mars 2026). Analyse de 30 millions de sources directement citées par 5 plateformes IA américaines. Documente le top 10 global (Reddit, YouTube, LinkedIn, Wikipedia, Forbes en tête) et surtout la divergence radicale par plateforme : G2 dans le top 5 de Perplexity uniquement, Forbes dans le top 5 de ChatGPT, Facebook/Yelp dominants côté Google AI Mode et AIO.

- Citation rate benchmarks 1M (Tom Wells, février 2026). Étude pédagogique forte sur la distinction citation vs retrieval (une page peut être récupérée comme candidate sans être citée dans la réponse finale). Propose des benchmarks opérationnels par plateforme — ChatGPT 2.0+, Google AI Mode 1.1-1.5, Perplexity 1.5-2.0 — avec la donnée frappante que 64 % des URLs sont jamais citées par Perplexity malgré leur présence dans la sidebar.
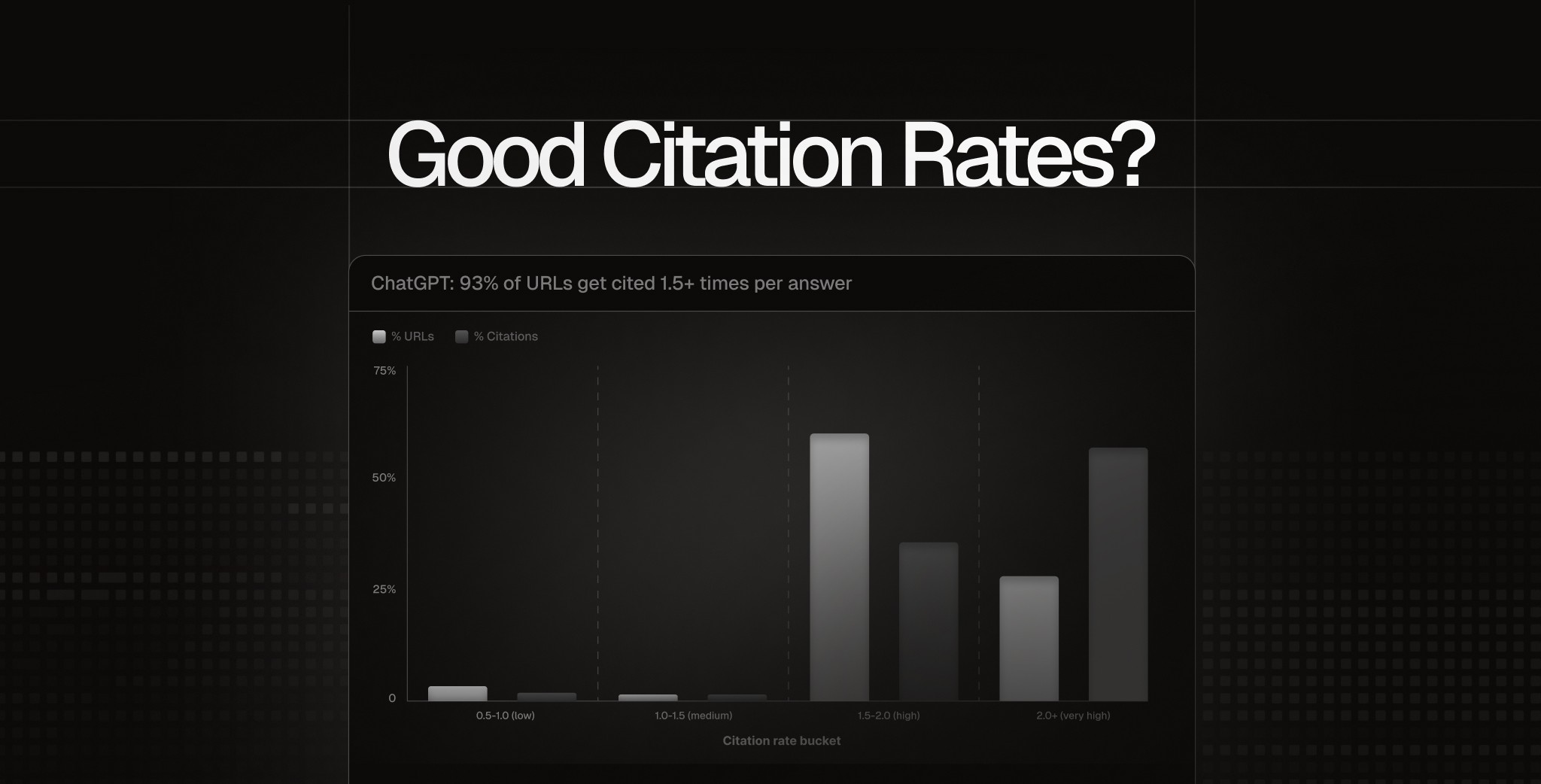
Dans le triple cadre, Peec AI couvre la couche Presence d'Aleyda et apporte une dimension critique sur la Readiness via ses falsifications publiées. Côté iPullRank, principalement des Channel Metrics avec attention particulière à la classification du sentiment et de la position. Les six métriques agentic ne sont pas mesurées.
Otterly : expérimentation contrôlée et études à grande échelle
Otterly se positionne comme une plateforme d'AI search monitoring orientée à la fois agences et équipes marketing internes. Basée à Vienne, la plateforme revendique en 2026 plus de 10 000 professionnels marketing utilisateurs et une reconnaissance sectorielle marquée — Gartner Cool Vendor AI in Marketing 2025, G2 High Performer Winter 2026, Best AI Search Software Solution European Search Awards 2026. Couverture : six plateformes (ChatGPT, Perplexity, Google AI Overviews, Google AI Mode, Gemini, Microsoft Copilot).
L'offre s'organise autour de modules complémentaires : Search Prompt Monitoring (interrogation automatique quotidienne sur une bibliothèque de prompts), AI Keyword Research Tool (transformation de mots-clés ou d'URL en prompts représentatifs), Brand Visibility Index, Domain Ranking & Analytics (suivi hebdomadaire des URL citées et de leur position), et un GEO Audit qui produit un SWOT et des recommandations tactiques.
Côté production research, Otterly publie deux types de contenu complémentaires qui constituent ensemble sa contribution sectorielle :
- La série GEO Experiment. Plus de dix expériences contrôlées publiées sur 2025-2026, chacune avec méthodologie exposée (typiquement 14 jours, 5-7 plateformes IA testées, page-level setup avec contrôle). Couvre llms.txt, Markdown vs HTML, schema markup, hidden text, image metadata, AI vs human content. Format pédagogique qui pose une hypothèse, expose le protocole, publie les résultats — y compris les négatifs.
- Les AI Search Studies à grande échelle. Études analytiques sur datasets internes avec méthodologie statistique formelle (Pearson correlation notamment). Deux études fondatrices à retenir :
- Two Different Googles (Thomas Peham, décembre 2025). 30 353 citations AI Mode + 2 498 citations AIO sur 100 top Googled queries allemandes. Démontre que Google AI Mode et Google AI Overviews fonctionnent comme deux systèmes IA distincts avec des règles séparées — 12× différentiel de volume de citations, divergence radicale dans l'attribution de marque. Étude qui a structuré le pattern AI Mode ≠ AIO repris ensuite dans tout le secteur

- URL AI Citation Study — 1M URLs (Rick Tousseyn, mai 2026). 1 028 959 URLs uniques analysées sur 6 plateformes, méthodologie Pearson correlation sur 15 attributs URL. Falsifie toutes les conventions SEO traditionnelles transférées au GEO — URL length, depth, hyphen count, TLD tous à corrélation Pearson < 0,04 (négligeable).

Dans le triple cadre, Otterly couvre la Presence d'Aleyda et apporte une dimension Readiness plus marquée que les deux autres via son GEO Audit. Côté iPullRank, c'est l'outil le plus équilibré entre Channel Metrics et Input Metrics grâce aux recommandations GEO ciblées. Les six métriques agentic restent absentes.
Ce qu'on retient de ce panorama
Les trois outils couvrent efficacement la couche Presence du cadre Aleyda et les Channel Metrics du cadre iPullRank. C'est leur cœur de métier, et ils le font avec des nuances de spécialisation qui se complètent plus qu'elles ne s'opposent.
Mais ce que ce panorama révèle surtout, c'est la valeur de leur production research. Profound, Peec AI et Otterly publient depuis 2024-2025 des études à grande échelle qui documentent plusieurs convergences sectorielles structurantes. Trois sont particulièrement notables :
- llms.txt n'a pas d'effet documenté sur la visibilité IA. Convergence Peec AI (article llms.txt hoax de Malte Landwehr en juillet 2025, mobilisant la position John Mueller) + Otterly (expérience contrôlée sur 90 jours et 62 100 visites bot, février 2026, 0,1 % de trafic sur le fichier) + documentation officielle Google (AI optimization guide, mai 2026). Trois sources indépendantes, trois méthodologies différentes, même conclusion.
- Google AI Mode et Google AI Overviews fonctionnent comme deux systèmes distincts avec des règles séparées. Convergence Otterly (étude Two Different Googles en décembre 2025, 30 353 citations AI Mode vs 2 498 citations AIO sur 100 top Googled queries) + Profound (étude Citation Categories en janvier 2026, 27 millions de citations sur 7 plateformes) + Peec AI (étude Top domains 30M, mars 2026). Trois échantillons massifs convergent sur le pattern d'asymétrie radicale entre les deux surfaces Google.
- Reddit domine en tête des citations IA cross-plateformes. Convergence Profound (datasets multiples) + Peec AI (étude 30M sources) + Otterly (étude 1 million+ citations). Reddit apparaît en position #1 ou #2 sur toutes les plateformes principales testées indépendamment par les trois acteurs.
Cela dit, aucun de ces trois outils n'embarque aujourd'hui les six métriques agentic posées par Mike King en mai 2026. Aucun ne mesure le triple cadre dans son entier. Le Business Impact d'Aleyda (couche 3 du framework) et les Performance Metrics d'iPullRank (couche 3 du modèle) restent à construire en interne via le suivi GA4, les survey discovery questions au signup, et les proxies third-party — aucun outil ne fait ça à votre place.
C'est cette double absence — la couche agentique côté technique, et la couche Business Impact côté business — qui dessine la matière de la section suivante.
Les limites communes des outils du marché
Le panorama de la section précédente a montré ce que les trois outils dominants savent faire. Cette section aborde l'autre versant : les limites qui leur sont communes, et qui définissent l'état actuel du marché de la mesure de visibilité IA. Ces limites ont été identifiées et formulées par plusieurs voix critiques du secteur et par les trois acteurs du panorama eux-mêmes. Aucune n'est imputable à un outil en particulier. Toutes sont structurelles.
1. Le non-déterminisme
Les LLMs sont par nature non déterministe. Une même requête peut produire des sorties différentes selon l'instance, l'heure, la session. Sans accès à la température, au seed et au contexte d'inférence, ce que les outils mesurent un jour n'est pas reproductible le lendemain. Les chiffres rapportés sont du bruit qui se fait passer pour du signal.
2. La personnalisation invisible
Les plateformes IA intègrent profil utilisateur, géolocalisation, historique de conversation, et — chez Google — un mécanisme de stateful chat documenté dans le brevet US20240289407A1 publié en mars 2024. Les outils de tracking interrogent les modèles avec un utilisateur neutre, c'est-à-dire personne. La mesure produit une situation qui ne représente aucun utilisateur réel.

3. L'absence de volumétrie agrégée publique
Aucun équivalent du volume de recherche Google n'existe pour les prompts IA. Lily Ray pose la limite directement dans sa rétrospective : les outils ne peuvent pas mesurer ce que les utilisateurs réels demandent en agrégat, parce qu'il n'y a pas de signal public d'usage côté plateformes IA. Conséquence : les estimations de share of voice IA n'ont pas de dénominateur stable, et restent — au mieux — directionnelles.
4. Le citation tracking sous-estime l'empreinte réelle
Dans une architecture agentic RAG, une requête utilisateur est décomposée en 5 à 20 sous-récupérations orchestrées. Votre contenu peut apparaître dans plusieurs de ces étapes sans figurer dans la citation finale rendue à l'utilisateur. Mike King documente dans Beyond RAG (mai 2026) une sous-estimation d'un facteur 3 à 10× chez les outils qui ne mesurent que la sortie finale du filtre. Le citation tracking traditionnel mesure les survivants, pas le filtre.
5. La fragmentation par système IA
Trois études convergentes documentent que les systèmes IA ne fonctionnent pas selon les mêmes règles. Otterly mesure un différentiel 12× de volume de citations entre Google AI Mode et Google AI Overviews sur 100 requêtes communes (étude Two Different Googles, décembre 2025). Profound documente que les distributions de sources sont radicalement différentes par plateforme (étude Citation Categories, 27M citations, janvier 2026). Peec retrouve cinq top 5 distincts par moteur (étude Top domains 30M sources, mars 2026). Une stratégie de visibilité IA unifiée est, par construction, inadaptée à un marché fragmenté.
6. La sous-représentation structurelle des sources off-site
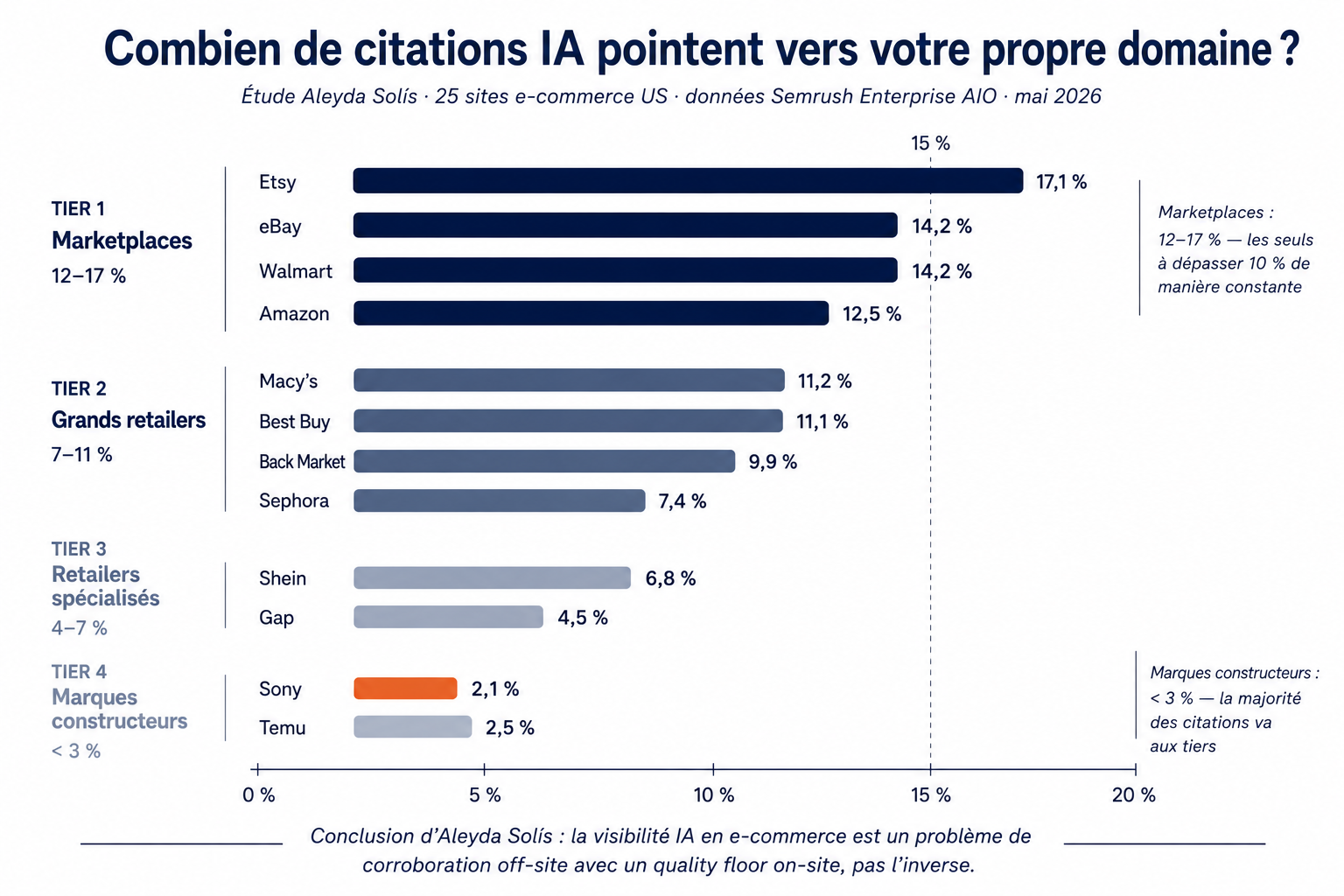
Sur les requêtes IA qui concernent votre propre marque, jusqu'à 97,9 % des citations pointent vers des sources tierces — Reddit, YouTube, Wikipédia, comparateurs, third-party reviews. L'étude d'Aleyda Solís sur 25 sites e-commerce US (mai 2026) documente le pattern : Sony pèse 2,1 % des citations sur ses propres requêtes, Etsy plafonne à 17,1 %. Même les leaders catégoriels restent sous les 15 %. La visibilité IA est structurellement un problème de corroboration off-site avec un quality floor on-site, pas l'inverse.
7. La prescription sans preuve dans la couche outils
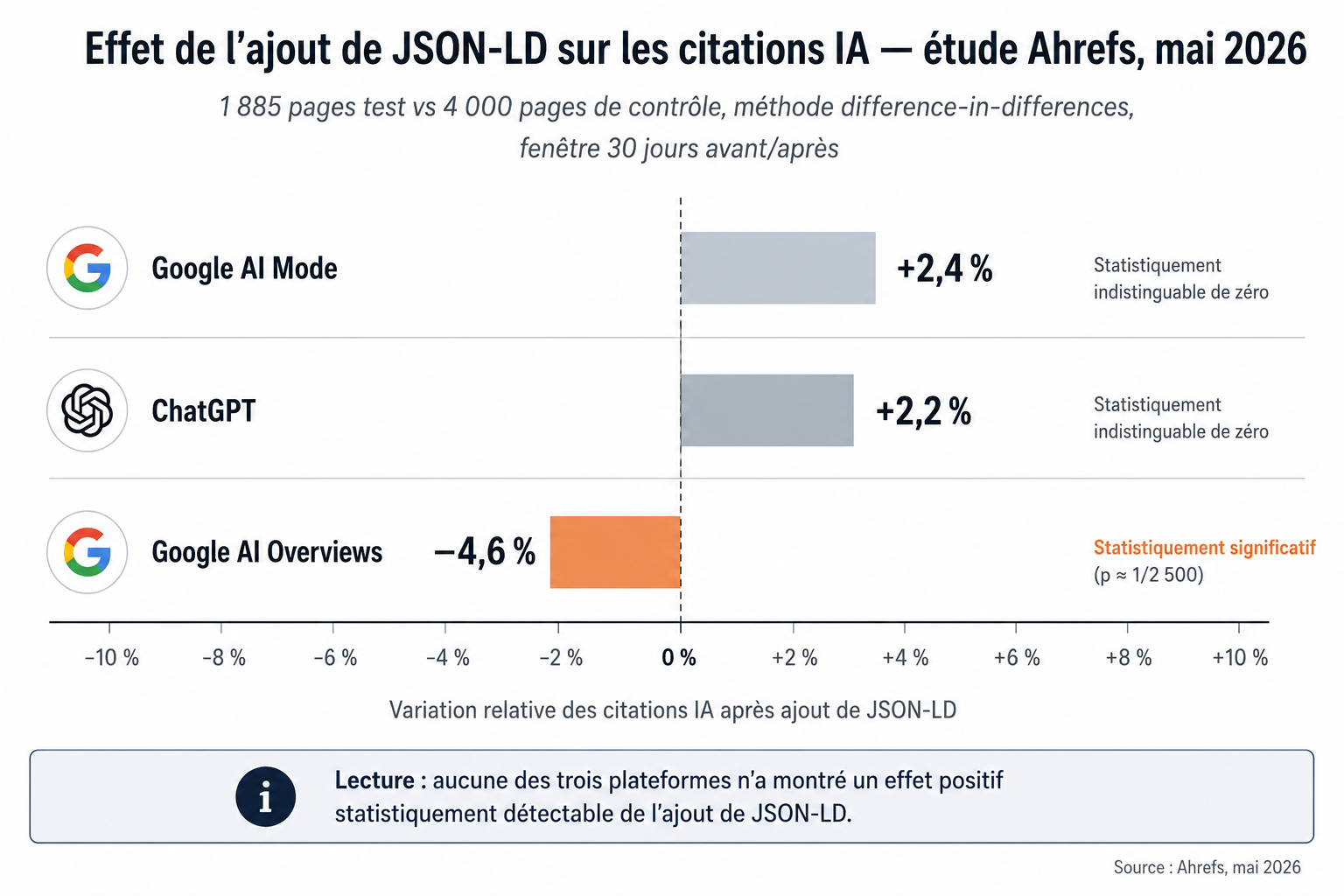
Beaucoup d'outils embarquent des recommandations techniques qui ne survivent pas aux études contrôlées récentes. Quatre sources convergent en 2025-2026 : Peec AI documente que llms.txt n'a aucun support officiel (article fondateur de Malte Landwehr, juillet 2025), Otterly mesure que les expériences schema ne produisent pas l'effet GEO promis (expérience contrôlée mars 2026), Ahrefs publie une RCT sur 1 885 pages qui falsifie l'effet du JSON-LD sur les citations IA (+2,4 % AI Mode, −4,6 % AI Overviews, mai 2026), et Google formalise dans son AI optimization guide officiel (mai 2026) que ni schema, ni llms.txt, ni Markdown ne sont requis pour la visibilité IA. La couche prescriptive vendue par une partie du marché est, selon la formule de Pedro Dias, un levier déconnecté du compteur.
Une critique sectorielle qui converge
Ces limites ne sont pas des défauts d'un outil en particulier — ce sont des contraintes structurelles communes à tous les outils du marché, posées par une communauté critique sectorielle dont les voix se complètent. Elles ne se résolvent pas par l'outil utilisé. Elles imposent une posture de pilotage différente : croiser les sources, lire un mouvement plutôt qu'une donnée absolue, accepter qu'une part du signal reste irréductiblement bruitée.
Sources — Documentation officielle, études et recherche académique
Google Search Central Documentation officielle, Optimizing your website for generative AI features on Google Search, publié le 15 mai 2026. URL : developers.google.com/search/docs/fundamentals/ai-optimization-guide. Position officielle de Google sur AEO, GEO, llms.txt, schema, chunking, et explication du mécanisme RAG + query fan-out en production.

Linehan, L. & Guan, X. — Ahrefs We Tracked 1,885 Pages Adding Schema. AI Citations Barely Moved., étude data publiée le 11 mai 2026. URL : ahrefs.com/blog/schema-ai-citations. Méthodologie : 1 885 pages traitées vs 4 000 pages contrôle, difference-in-differences, fenêtre 30 jours. Résultats : Google AI Mode +2,4 %, ChatGPT +2,2 % (non significatifs), Google AI Overviews −4,6 % (p ≈ 1/2 500).

Oumi pour le New York Times Étude commanditée sur la précision et l'ungroundedness des AI Overviews de Google, publiée en avril 2026. Méthodologie : 4 326 requêtes du benchmark SimpleQA testées en deux vagues sur Gemini 2 (octobre 2025) puis Gemini 3 (février 2026). Résultats : 85 % → 91 % d'accuracy ; 37 % → 56 % de réponses correctes mais ungrounded.
Aggarwal, P. et al. GEO: Generative Engine Optimization, paper académique présenté à KDD 2024. ArXiv : 2311.09735. Benchmark de 10 000 requêtes, 9 méthodes d'optimisation testées. Findings qui marchent : citations, quotations, statistiques, fluidité, simplification. Findings qui ne marchent pas : keyword stuffing (sous la baseline). Schema, structured data, FAQ markup, heading hierarchy non testés.
Google — Brevet US20240289407A1 Stateful chat session for generative AI conversations, déposé en mars 2024. Documente le mécanisme de mémoire persistante côté utilisateur en chat IA, antérieur à l'introduction de ChatGPT Memory. Source primaire pour la dimension personnalisation invisible du H2 1.

Anthropic Research Mapping the Mind of a Large Language Model, publication de recherche, mai 2024. URL : anthropic.com/research/mapping-mind-language-model. Référence pour la reconnaissance officielle, par un constructeur, de l'opacité partielle des LLMs face aux méthodes d'interprétabilité actuelles.
