Mémoire de marque : être retenu, pas seulement récupéré
L'IA choisit les marques dans sa mémoire avant de chercher ses sources. Comprendre la visibilité paramétrique, pourquoi la familiarité décide au moment du choix, et les leviers d'entité pour entrer dans la mémoire des modèles.
Le 7 mai 2026, ChatGPT a changé quelque chose sans l'annoncer : les noms de marque dans ses réponses sont devenus des liens cliquables vers les sites des marques en question. En une semaine, les visites quotidiennes envoyées par ChatGPT vers les sites de marque ont environ doublé (Profound, mai 2026). Être nommé dans une réponse d'IA n'est plus seulement une affaire de perception : c'est devenu un canal de trafic mesurable. Reste la question qui compte — qu'est-ce qui décide qu'une marque est nommée ?
Mon article précédent s'arrêtait sur ce seuil. J'y montrais comment une IA sélectionne quelques phrases de votre page au moment où elle la récupère, et je concluais sur une variable qui échappe à ce mécanisme : être une entité suffisamment établie pour que le modèle s'en souvienne sans avoir à chercher. C'est ce mécanisme là que je reprends ici. Le grounding traite de ce que l'IA retient de votre page quand elle va la chercher ; cet article traite de ce que le modèle retient de votre marque avant même de chercher — ce qui est inscrit dans sa mémoire paramétrique (parametric memory), constituée à l'entraînement.
Cette distinction n'aurait qu'un intérêt théorique si les deux couches allaient ensemble. Or elles restent séparées, et la donnée est claire : dans la majorité des cas, une page citée en source ne vaut pas une marque nommée — votre contenu peut travailler pendant que votre marque reste invisible, voire pendant qu'un concurrent récolte la recommandation. Être récupéré ne suffit plus. Il faut être retenu.
Je vais d'abord poser ce découplage et le mécanisme qui l'explique, puis le cadre pour penser ces deux visibilités, montrer pourquoi la mémoire tranche au moment du choix, comment elle se mesure, et terminer par les leviers — qui ne sont pas ceux du contenu.
Résumé exécutif
- Être cité ne prouve pas que vous existez pour le modèle : environ 62 % des citations IA sont des « citations fantômes » — la page sert de source, la marque n'est jamais nommée dans la réponse . Le modèle choisit les marques dans sa mémoire, puis cherche des sources pour étayer.
- Il existe deux visibilités distinctes : la visibilité dynamique (ce que l'IA trouve quand elle cherche sur le web) et la visibilité paramétrique (ce que le modèle sait sans chercher). Elles bougent indépendamment, et un score unique qui les confond ne pilote rien.
- Au moment du choix, c'est la familiarité qui tranche : face à une réponse d'IA, les utilisateurs filtrent d'abord par la confiance dans la marque, ensuite par la pertinence. Et plus l'utilisateur délègue à la machine — jusqu'à l'agent qui transige seul —, moins une marque floue a sa place.
- La mémoire de marque n'est plus une métaphore : elle se quantifie (ancrage associatif, perception latente), mais elle varie d'un modèle à l'autre et se pilote en tendance, pas en photo.
- Les leviers sont des leviers d'entité, pas de contenu : attacher le nom de marque aux affirmations clés, construire le graphe d'entité, gagner des mentions tierces en contexte de recommandation. Et ils opèrent sur des cycles d'entraînement — des mois, pas des jours.
Sommaire
- La citation fantôme : cité sans exister
- Deux visibilités, deux jeux
- Pourquoi la mémoire tranche au moment du choix
- La mémoire de marque se mesure — en tendance
- Entrer dans la mémoire : des leviers d'entité, pas de contenu
La citation fantôme : cité sans exister
Une précision de vocabulaire d'abord, parce que tout le sujet tient dans cette distinction. Quand une IA répond, votre site peut apparaître de deux façons : comme citation — votre page est liée en source, dans le corps de la réponse ou en note — ou comme mention — votre marque est nommée dans le texte lui-même. On les confond d'autant plus facilement que les outils de suivi les mélangent souvent. Ce sont pourtant deux événements distincts, produits par deux mécanismes distincts.
Et ils se découplent massivement. En juin 2026, Semrush et Kevin Indig ont mesuré l'écart sur des milliers d'apparitions de domaines à travers plusieurs moteurs : environ 62 % des citations IA sont des citations fantômes (ghost citations) — la page est utilisée comme source, mais la marque n'est jamais nommée dans la réponse. Chaque moteur a son profil : dans cette mesure, quand une marque apparaît dans Gemini, elle est nommée dans le texte 83,7 % du temps mais citée en source 21,4 % seulement ; ChatGPT fait l'inverse — 87 % de citation, 20,7 % de mention. Même marque, même question, deux comportements opposés. Première conséquence, pratique : un outil de suivi peut vous montrer « visible » sur un moteur où personne ne lit jamais votre nom.
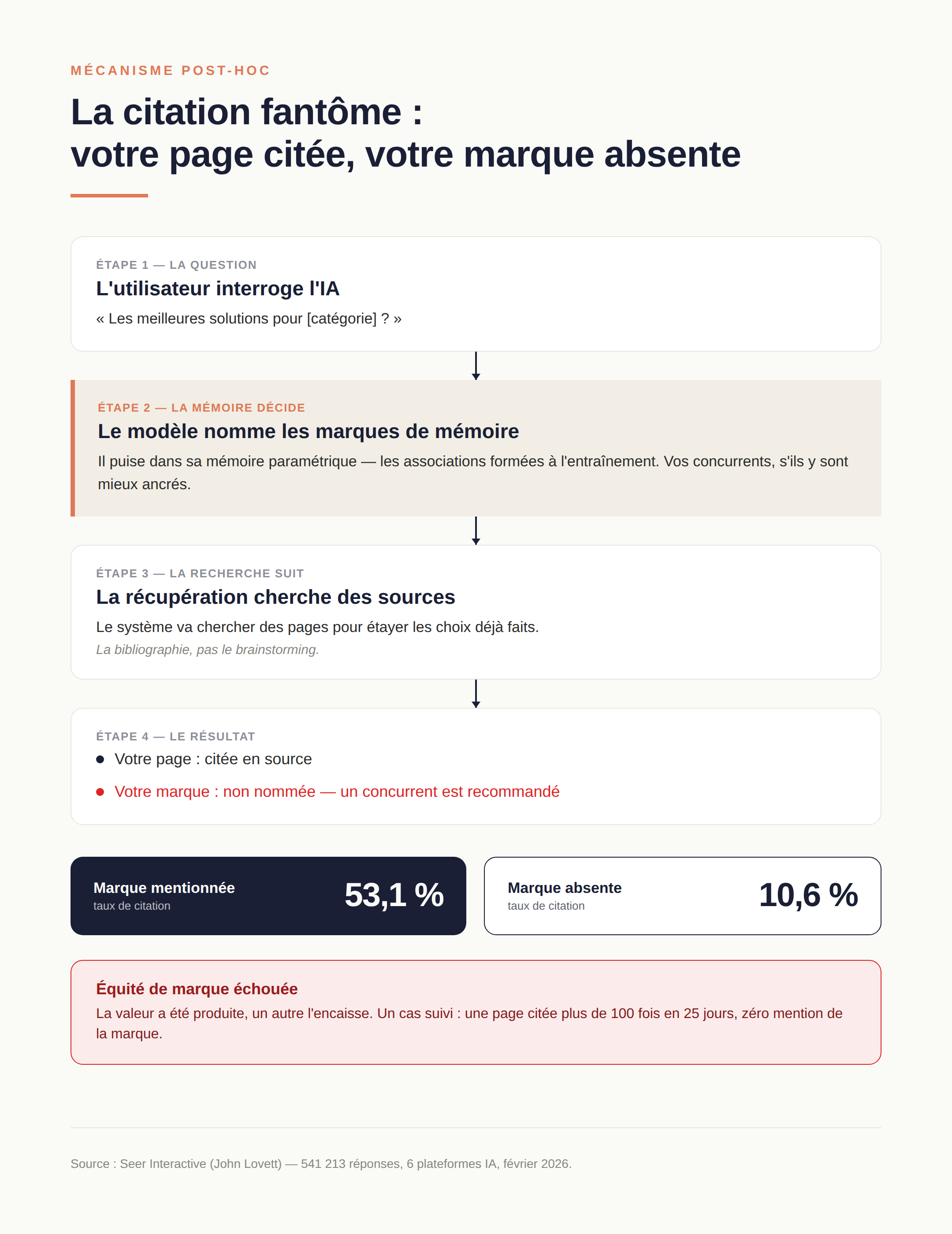
Le cas le plus coûteux porte un nom : la citation fantôme compétitive. John Lovett (Seer Interactive) l'a documentée sur 541 213 réponses d'IA, 20 marques et 6 plateformes en février 2026 : votre page est citée en source, votre marque n'est pas nommée — et un concurrent est recommandé dans la même réponse. Son cas d'école : le billet d'un éditeur de logiciels de conformité, cité plus de 100 fois en 25 jours comme référence sur un cadre réglementaire, sans une seule mention de la marque. L'IA se servait du contenu comme matière première tout en recommandant les concurrents par leur nom. Lovett appelle ça de l'équité de marque échouée : la valeur a été produite, quelqu'un d'autre l'encaisse.
Pourquoi ce découplage ? Parce que la séquence n'est pas celle qu'on imagine. L'intuition voudrait que l'IA trouve les bonnes sources, puis en tire les marques à recommander. Les données de Lovett disent l'inverse : le modèle décide d'abord quelles marques nommer — en puisant dans sa mémoire paramétrique, les associations constituées à l'entraînement — puis la récupération va chercher des sources pour étayer ces choix. Sa formule résume le renversement : « les citations sont la bibliographie, pas le brainstorming ». La signature chiffrée est nette : quand une marque est mentionnée dans une réponse, son taux de citation atteint 53,1 % ; quand elle ne l'est pas, il tombe à 10,6 %. Si la citation causait la mention, l'écart irait dans l'autre sens.
Kevin Indig nomme la couche sous-jacente : le biais primaire (primary bias) — les associations marque-attributs que le modèle détient avant toute recherche web, héritées de son entraînement. « Pas cher », « fiable », « pour les grandes équipes » : ces étiquettes préexistent à la requête, et elles pèsent sur ce que la réponse nommera, même quand votre page entre dans le périmètre de récupération.
Deux précautions pour finir cette section, parce qu'elles font partie du sujet. D'une part, ces deux mesures viennent de dispositifs distincts — Scrunch via Seer pour l'une, Semrush pour l'autre — et leurs pourcentages ne s'additionnent pas ; c'est leur convergence qui fait preuve, pas leur cumul. D'autre part, la séquence « la marque d'abord, la source ensuite » est une démonstration comportementale : Lovett n'a pas accès aux mécanismes internes des modèles, il observe des régularités sur un grand volume — six tests indépendants sur 362 188 réponses — qui rendent l'explication inverse intenable. C'est solide, ce n'est pas une preuve d'architecture.
Le constat tient en une phrase : votre contenu peut franchir le seuil de la récupération sans que votre marque franchisse celui de la mémoire. Deux seuils, deux systèmes — et donc deux visibilités à penser séparément. C'est l'objet de la section suivante.
Deux visibilités, deux jeux
Ce découplage demande un cadre, et il existe. Gianluca Fiorelli distingue la visibilité dynamique (dynamic visibility) — ce que le modèle trouve quand il cherche sur le web — de la visibilité paramétrique (parametric visibility) — ce que le modèle sait quand il ne cherche pas, par la seule force de ce que son entraînement a retenu de votre entité.

La première couche, vous la connaissez : c'est le jeu décrit dans mes deux articles précédents. Une requête décomposée en sous-requêtes, des pages récupérées, des phrases extraites, une réponse assemblée. Ce jeu se joue au niveau de la page, il récompense la récupérabilité et l'écriture, et il se rejoue à chaque question. La seconde couche se joue au niveau de l'entité, elle se constitue sur des cycles d'entraînement, et elle est déjà jouée quand la conversation commence.
L'erreur serait de croire la couche paramétrique marginale — un filet de sécurité pour les rares fois où l'IA ne cherche pas. C'est l'inverse : ne pas chercher est un comportement massif. Je terminais l'article précédent sur ce chiffre : la version gratuite de ChatGPT lance une recherche web dans environ 11 % des cas, contre 47 % pour la payante. Pour la majorité des utilisateurs — ceux du gratuit —, la réponse vient donc d'abord de la mémoire. Quand quelqu'un demande « quel outil pour faire X » à une IA qui ne cherche pas, votre site n'a aucune chance d'être récupéré : soit votre marque est déjà dans la réponse parce que le modèle l'a retenue, soit vous n'existez pas pour cette conversation. Il n'y a pas de deuxième tour.
Et même quand l'IA cherche, les deux couches ne fusionnent pas — elles interagissent. La citation fantôme de la section précédente est exactement ça : une visibilité dynamique (votre page est récupérée et citée) sans visibilité paramétrique (votre marque n'est pas dans la mémoire qui décide des noms). Le cas inverse existe tout autant : une marque nommée de mémoire, sans qu'aucune page ne soit citée — le profil dominant de Gemini dans la mesure de la section 1. Les deux couches peuvent être fortes, faibles, ou désaccordées, et c'est le désaccord qui coûte le plus cher parce qu'il est invisible dans les rapports.
D'où la conséquence pour le pilotage : un « score de visibilité IA » unique, qui fond citations et mentions en un chiffre, additionne deux grandeurs qui ne bougent pas ensemble, ne récompensent pas le même travail et n'échouent pas de la même façon. J'ai détaillé ailleurs ce que les outils de suivi mesurent vraiment ; la distinction paramétrique/dynamique y ajoute une grille de lecture : la plupart mesurent la couche dynamique — des sorties, requête par requête — et touchent à peine la couche lente, celle qui décide des noms.
Deux visibilités, donc deux jeux. Le jeu dynamique, vous savez désormais le jouer : c'était l'objet du Grounding. Reste à comprendre pourquoi le jeu paramétrique est en train de devenir le plus décisif des deux — et la réponse n'est pas dans les machines, elle est dans le comportement des utilisateurs.
Pourquoi la mémoire l'emporte au moment du choix
Si la couche paramétrique prend ce poids, c'est d'abord parce que les utilisateurs ont changé de comportement face aux réponses d'IA — et que ce comportement favorise structurellement les marques déjà connues.
La première étude UX indépendante des AI Overviews l'a établi en filmant 69 utilisateurs face à de vraies recherches : le choix du résultat suit un filtre en deux temps. La question « est-ce que je fais confiance à cette source ? » passe avant « est-ce que ça répond à ma question ? ». Quand une marque reconnue figure parmi les options, elle est choisie en premier dans 58 % des cas. L'autorité précède la pertinence — c'est un renversement de l'ordre qui régissait vingt ans de pages de résultats, où l'on triait d'abord par adéquation à la requête. Et la relation joue dans les deux sens : la réponse d'IA emprunte sa crédibilité aux marques qu'elle affiche. Les utilisateurs valident ou rejettent un AI Overview selon qu'un nom familier s'y trouve. Votre marque ne profite pas seulement de la réponse ; elle la cautionne.
Le même dispositif de recherche, appliqué ensuite à l'AI Mode de Google, a poussé le constat plus loin : sur 250 tâches observées, la médiane est de zéro clic externe — on lit la réponse, on décide à l'intérieur, on ne sort que pour transiger. Et quand les participants devaient trancher dans une catégorie qu'ils connaissaient mal, le facteur d'influence numéro un était la confiance dans la marque : face à des options inconnues, on se rabat sur le nom qu'on a déjà rencontré. Dans une surface qui ne montre ni dix liens ni la possibilité de comparer longuement, la familiarité n'est plus un avantage : c'est le mécanisme de décision lui-même.
D'où une conséquence qui inverse une habitude de mesure : la mention vaut plus que le clic. Une marque nommée dans une réponse, même sans lien, dépose de la familiarité — celle-là même qui tranchera la prochaine décision, dans l'IA ou ailleurs. C'est l'argument de Kevin Indig pour faire des mentions la métrique prioritaire, devant les citations et le trafic. Le 7 mai 2026 a simplement rendu cette logique visible dans les outils d'analyse : depuis que ChatGPT transforme les noms de marque en liens, la mention porte aussi le clic — le travail de mémoire qui faisait gagner en silence se met à apparaître dans le trafic référent.
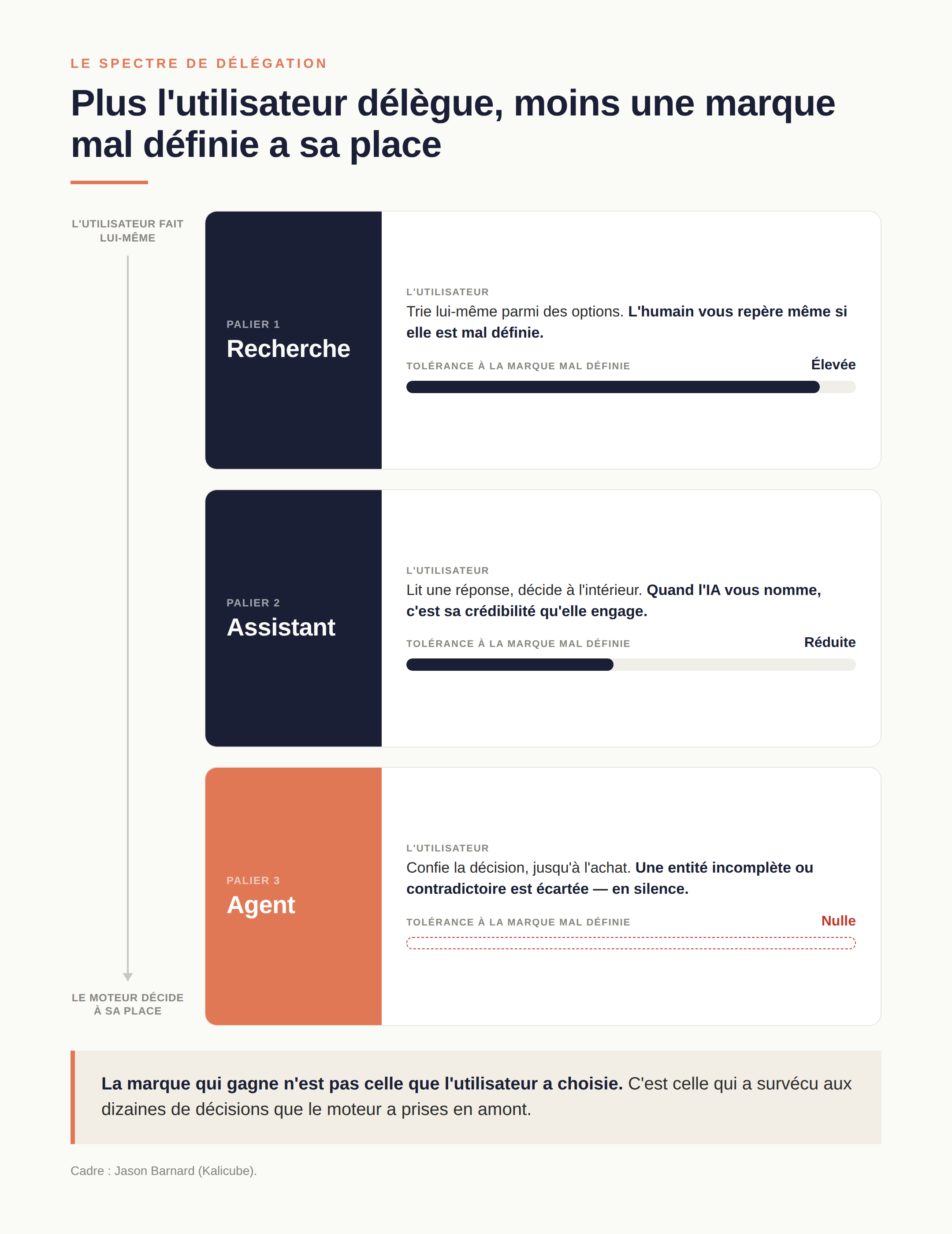
Reste la dynamique qui rend tout cela cumulatif : la délégation. Jason Barnard décrit une frontière mobile entre ce que l'utilisateur fait lui-même et ce qu'il confie au moteur — chercher, présélectionner, jusqu'à acheter. Or chaque cran de délégation réduit la tolérance à la marque floue. La recherche classique la tolère : l'humain trie. Le mode assistant en tolère moins : quand l'IA vous nomme, c'est sa crédibilité qu'elle engage. L'agent n'en tolère aucune : devant une entité aux informations incomplètes ou contradictoires, il l'écarte discrètement — et l'utilisateur ne saura jamais que vous faisiez partie des options. La formule de Barnard résume l'enjeu : la marque qui gagne n'est pas celle que l'utilisateur a choisie, c'est celle qui a survécu aux dizaines de décisions que le moteur a prises en amont.
Un dernier élément complète le tableau, côté machine cette fois : quand le mode raisonnement de ChatGPT est actif, une marque rencontrée dès les requêtes exploratoires peut se maintenir dans les réponses jusqu'à l'étape de sélection finale — une persistance qui n'apparaît jamais en mode minimal (mesure Semrush sur GPT-5.2, 20 parcours d'achat). Être présent tôt dans le parcours n'est plus seulement de la notoriété : c'est une position que le système reconduit jusqu'à la décision.
Familiarité qui filtre, mention qui dépose, délégation qui élimine le flou, persistance qui reconduit : tout converge vers une même conclusion. La partie décisive se joue dans une mémoire que personne ne voit. La question suivante est donc naturelle — peut-on la regarder ?
La mémoire de marque se mesure — en tendance
Une mémoire qu'on ne voit pas semble impossible à piloter. Elle ne l'est plus tout à fait : deux approches ont émergé pour la regarder — faire parler le modèle, et regarder à l'intérieur du modèle.
La première est d'une simplicité désarmante. Dan Petrovic a demandé 200 000 fois à Gemini de nommer « 100 marques au hasard ». Sommé de produire de l'aléatoire, le modèle révèle en réalité sa distribution interne : certaines marques reviennent à presque chaque tirage, d'autres une seule fois — et cette non-uniformité est précisément le signal. En construisant ensuite le graphe des associations entre marques (2,9 millions de nœuds) et en y appliquant un PageRank personnalisé, il obtient un score d'ancrage associatif : non pas « à quelle fréquence le modèle pense à cette marque », mais à quel point elle est intégrée dans sa structure d'associations. La nuance compte — une maison comme Maison Margiela n'est presque jamais citée spontanément, mais score haut parce qu'elle occupe un carrefour dense d'associations du luxe. Ce score mesure la mémoire d'un modèle, pas la force d'une marque sur son marché : c'est une radiographie de ce que Gemini a retenu, avec ses angles morts, pas une étude de notoriété.
Et cette radiographie change d'un modèle à l'autre. La même méthode appliquée à Gemma 4 fait apparaître un palmarès partiellement différent — chaque modèle a retenu le monde à sa façon, selon son corpus et son entraînement. Il n'existe donc pas une mémoire de marque, mais une par modèle ; ce qui rejoint un constat déjà posé pour les citations : on ne mesure pas « les IA », on mesure chaque moteur séparément.
La seconde approche va voir à l'intérieur. Andrea Volpini applique les outils d'interprétabilité d'Anthropic à un modèle ouvert pour observer quel cadre sémantique latent s'active quand un nom de marque apparaît — avant toute génération de réponse. Sur Renault, son exemple public : un pôle « constructeur français historique » nettement dominant, un pôle « acteur de la transition électrique » présent mais secondaire. Si la marque veut être perçue comme la seconde et que le modèle a retenu la première, aucune optimisation de page ne corrigera l'écart — le diagnostic précède le levier. Une précaution s'impose ici, et elle est posée par Volpini lui-même : l'idée qu'on puisse déplacer cette perception latente en enrichissant les données structurées et les graphes de connaissances est à ce stade un protocole de test, pas un résultat démontré. C'est une direction de recherche prometteuse, pas un acquis.
Pour le pilotage courant, nul besoin d'aller jusqu'à l'interprétabilité. Trois questions suffisent à structurer la mesure, formulées par John Lovett : êtes-vous vu quand l'IA répond dans votre catégorie (part des réponses qui mentionnent votre marque) ; êtes-vous cru (exactitude de ce que l'IA dit de vous, confrontée à un référentiel de faits de marque qu'il appelle le Brand Canon) ; êtes-vous choisi (ce que les interactions influencées par l'IA produisent en aval). À quoi s'ajoute l'indicateur de santé né de la section 1 : la part de citations fantômes compétitives dans vos citations totales — si elle baisse, le travail d'entité paie ; si elle monte, votre contenu progresse plus vite que votre marque.
Une discipline traverse tout cela : ces mesures se lisent en tendance. Les réponses d'IA varient d'un tirage à l'autre, les modèles changent sans préavis, et un chiffre ponctuel ne dit presque rien. La posture juste est celle que Lovett résume en quatre mots — viser la direction, pas la perfection : des mesures répétées, un cap trimestriel, pas une photo.
Savoir où vous en êtes est une chose. Reste la question pratique : comment entre-t-on dans cette mémoire ? C'est l'objet de la dernière section — et les leviers ne sont pas ceux qu'on croit.
Entrer dans la mémoire : des leviers d'entité, pas de contenu
Le réflexe naturel face à une marque absente des réponses est de produire davantage — plus de pages, plus de guides, plus de profondeur. C'est précisément le réflexe que les données invalident : si le problème est un problème de reconnaissance d'entité, ajouter du contenu n'y change rien, et peut même l'aggraver — plus de matière récupérable, c'est plus de citations fantômes potentielles. L'observation de Lovett est sans ambiguïté sur ce point : des concurrents plus petits, avec moins de contenu mais une entité plus nette, surclassent des acteurs établis dans les mentions. La taille ne protège pas ; la netteté, si. Trois leviers en découlent.

Attacher votre nom à vos idées.
L'extraction phrase à phrase décrite dans le Grounding a une conséquence qu'on ne tire presque jamais : si votre nom de marque n'est pas dans la phrase qui porte l'idée, l'IA absorbe l'idée et laisse le nom. Une page qui écrit « il existe trois approches pour répondre à cette exigence réglementaire » nourrit la réponse de l'IA de manière anonyme ; la même page qui écrit « l'approche que [Marque] applique consiste à… » rend le nom inséparable de l'affirmation. Faire de la marque le sujet grammatical des phrases que l'IA est susceptible d'extraire — pas partout, sur les affirmations clés — est le seul de ces trois leviers qui se joue dans votre propre texte.
Construire le graphe d'entité.
Wikidata renseigné, balisage Organization avec ses liens sameAs, nom canonique strictement identique partout, auteurs reliés à l'organisation. Arrivé ici, un lecteur de mon article sur les citations IA peut légitimement froncer les sourcils : j'y classais les données structurées parmi les faux leviers de citation. Les deux affirmations tiennent ensemble, et la distinction est temporelle. Au moment où l'IA compose une réponse, le balisage est ignoré ou lu comme du texte brut — comme levier de citation immédiat, le constat n'a pas bougé. Mais ce même balisage alimente depuis des années les graphes de connaissances — celui de Google, Wikidata — dont les profils d'entités sont massivement présents dans les corpus sur lesquels les modèles s'entraînent. Le balisage n'atteint pas la réponse d'aujourd'hui ; il peuple la mémoire des modèles de demain. Fiorelli a la bonne analogie : c'est un enregistrement au registre du commerce, pas une publicité — on ne le fait pas pour vendre demain matin, on le fait pour être formellement reconnaissable par les systèmes qui décident ensuite de vous nommer.
Gagner des mentions tierces en contexte de recommandation.
C'est le levier au rendement le plus documenté, et il est hors de votre site : 85 % des mentions de marque dans les réponses IA à forte intention d'achat proviennent de pages tierces (AirOps, 2026). Une étude Ahrefs sur 75 000 marques pointe dans la même direction : les mentions — YouTube en tête, puis les mentions web de marque — sont les facteurs les plus corrélés à la visibilité IA, là où les backlinks et le volume de pages ne pèsent presque rien. Ce qui compte n'est pas seulement d'être nommé, mais à côté de quoi : les co-occurrences entre votre marque et les attributs que vous voulez lui voir associer — c'est dans ces voisinages répétés que se forment les associations de la section précédente. Les relations presse retrouvent ici un rôle direct : une mention de votre nom canonique dans un média de référence n'est plus seulement un lien, c'est un signal d'entraînement.
Reste la donnée la plus inconfortable de toutes : le temps. Aucun de ces leviers n'agit à l'échelle d'une campagne. Le cas client suivi par Lovett le montre crûment — langage de marque ajouté à une page citée plus de cent fois, et vingt-neuf jours plus tard, toujours zéro mention : les modèles apprennent du web qu'ils ont indexé, à leur rythme, version après version. Ce que vous publiez aujourd'hui est un investissement dans la perception de la prochaine génération de modèles, pas de celle qui répond ce soir. C'est frustrant à l'échelle d'un trimestre ; c'est aussi ce qui rend ce travail cumulatif. Barnard le formule en une consigne : entraîner le socle, pas seulement le signal — chaque preuve de confiance posée aujourd'hui nourrit des associations dont tous les modèles futurs hériteront, y compris ceux qui n'existent pas encore. Pour une marque établie, c'est une rente qui se constitue ; pour un challenger, le chemin existe mais il est exigeant — affirmer qui l'on est, le faire corroborer par assez de sources tierces pour que les moteurs disposent de la preuve.
Pour conclure : un travail qui compose
Résumons le fil. Une page citée ne vaut pas une marque retenue : dans la majorité des cas, l'IA se sert du contenu sans nommer son auteur, parce qu'elle choisit les marques dans sa mémoire avant de chercher ses sources. Il y a donc deux visibilités — celle que l'IA trouve en cherchant, celle que le modèle sait sans chercher — et la seconde prend l'avantage à mesure que les utilisateurs délèguent : la familiarité filtre, la mention dépose, l'agent écarte le flou. Cette mémoire se mesure, modèle par modèle et en tendance. Et on y entre par l'entité, pas par le volume : un nom attaché à ses idées, un graphe d'entité net, des mentions tierces dans les bons voisinages.
Ce qui change au fond, c'est la temporalité du métier. La visibilité dynamique se travaille à l'échelle de la page et se constate en semaines ; la visibilité paramétrique se travaille à l'échelle de l'entité et se constate en générations de modèles. La première récompense l'optimisation, la seconde récompense la constance — dire la même chose de soi, partout, longtemps, et le faire confirmer par d'autres. C'est un déplacement inconfortable pour une discipline habituée à mesurer vite. C'est aussi une bonne nouvelle : ce travail-là ne se remet pas à zéro à chaque mise à jour, il s'accumule dans chaque modèle qui s'entraîne.
Avec le Grounding, vous avez la couche de la page : ce que l'IA retient quand elle vous lit. Avec cet article, la couche de l'entité : ce que le modèle retient quand personne ne cherche. Reste la troisième pièce, la plus demandée : comment suivre tout cela en pratique — quels indicateurs, quels outils, à quelle fréquence, et avec quel niveau de confiance dans les chiffres. Ce sera l'objet d'un prochain article, consacré au suivi de visibilité sur les IA.