Mesurer sa présence IA : output, retrieval et latent
On confond souvent la courbe qu'on regarde et le levier qu'on actionne. Ce cadre mesure votre présence dans les réponses IA en trois couches — output, retrieval, perception de marque — avec les instruments à suivre et la discipline qui les rend fiables.
Les solutions de suivi de visibilité IA se multiplie et la lecture des performances devient de plus en plus complexe. Le problème est de savoir ce que mesure réellement ces kpis et ce qu'ils apportent comme performance réelle.
Dans un précédent article, nous avons examiné ce que ces outils mesurent réellement — et leurs angles morts. La question n'est plus ce que le marché mesure, mais ce que vous devez mesurer, et comment l'organiser en un dispositif qui éclaire vos décisions.
Ce dispositif tient en trois couches :
- L'output : ce que l'IA dit de vous, dans la réponse générée.
- Le retrieval : ce qu'elle parvient à récupérer de vos pages au moment de répondre.
- Le latent : ce qu'elle « retient » de votre marque, avant même d'aller chercher.

Les deux premières relèvent de la visibilité dynamique — récupérable, observable, influençable par les fondamentaux que vous connaissez déjà. La troisième relève de la visibilité paramétrique — la mémoire de marque, plus lente à former, plus difficile à instrumenter. C'est, côté mesure, le prolongement direct de la distinction posée dans Grounding et Mémoire de marque.
Avant d'entrer dans ces trois niveaux, une étape que la plupart des dispositifs passent : la façon même dont vous prenez vos mesures. Et après elles, la discipline sans laquelle tout le reste produit du bruit.
La couche d'entrée : un jeu de prompts représentatif
Les trois niveaux qui suivent ne valent que par ce qu'on leur donne à mesurer. Et ce qu'on leur donne, c'est une liste de prompts — les questions qu'on pose aux moteurs pour observer ce qu'ils répondent sur une entité ou une marque. La plupart des outils propose ce suivi et c'est la pertinence et l'exhaustivité de ce jeu de prompts qui définira la pertinence et la fiabilité du suivi réalisé.

Une liste de prompts est une simple liste de questions répondant chacune à une intention unique. Un ensemble représentatif — ce qu'Aleyda Solís a formalisé sous le nom de prompt library — est un système d'échantillonnage : un sous-ensemble structuré des parcours assistés par IA qui comptent pour votre activité. Représentatif, pas exhaustif. Vous n'avez pas besoin de toutes les formulations possibles ; vous avez besoin des groupes de requêtes qui décident, répartis sur les dimensions qui changent la réponse — étape du parcours, ligne produit, audience, marché, et surtout les contraintes réelles d'un acheteur. Un budget, une taille d'entreprise, une exigence de conformité réécrivent entièrement ce qu'un moteur recommande.
D'où une règle de méthode : on construit la matrice avant d'écrire le moindre prompt. Produit × audience × marché × étape × contrainte. C'est ce qui rend votre jeu représentatif.
A cela s'ajoute une variable : comment vous le demandez. La même intention, posée en mots-clés courts ou en question conversationnelle, ne fait pas remonter les mêmes sources, ni les mêmes marques. Un jeu représentatif fixe donc aussi la forme des requêtes — sans quoi vous mesurez votre propre manière de taper autant que votre présence réelle.
Reste à mesurer efficacement, et deux principes entrent en jeu. D'abord, la présence se lit en fréquence : une sortie isolée est un échantillon, pas un classement. « Cité 4 fois sur 5 exécutions » est une donnée ; « cité aujourd'hui » n'en est pas une. Le protocole minimal en découle — trois à cinq exécutions par prompt, sur une fenêtre de 24 à 72 heures, en session propre et déconnectée, langue et marché définis, plateforme et version notées. Ensuite, on n'agrège jamais les plateformes en un score unique : AIO, AI Mode, ChatGPT, Perplexity, Gemini ne mesurent pas la même population, et les agréger masque précisément là où se trouve l'opportunité. Ce principe reviendra — c'est le fil rouge de tout le dispositif.
Cette couche d'entrée ne produit aucun chiffre. Elle décide juste si tout ce qui suit mesure un signal ou du bruit. On peut entrer dans la première couche : ce que l'IA dit de vous.
La couche output : ce que l'IA dit de vous
C'est la couche visible — celle que tout le monde suit, et celle qu'on lit le plus mal. L'output, c'est ce que le moteur dit de vous dans la réponse qu'il génère : votre marque apparaît-elle, est-elle citée, avec quelles sources, et dans quels termes ?
Seer (John Lovett) ramène la mesure à trois questions — être vu, être cru, être choisi — avec un indicateur par question. Le premier concerne directement l'output : l'AI Signal Rate, soit le nombre de réponses où votre marque apparaît, rapporté au nombre de questions posées dans votre catégorie. Lu, comme on l'a vu, en fréquence sur des exécutions répétées et plateforme par plateforme. Pour situer l'ordre de grandeur, Lovett place les leaders d'une catégorie entre 60 et 80 % de présence, un challenger qui démarre plutôt autour de 5 à 10 % — l'enjeu restant de suivre la direction, pas d'atteindre un chiffre parfait. Décliné face à un ensemble concurrentiel, ce même indicateur donne votre part de voix.
Une prudence structurelle, propre à ce taux. En SEO classique, on ne lit jamais un rang sans son volume de recherche. Côté IA, cela n'existe pas : aucune plateforme n'expose la fréquence des prompts, et ce qui se vend comme « volume de prompts » est de la donnée mot-clé déguisée. L'AI Signal Rate dit donc si votre présence est stable ou non, pas combien de personnes ont posé la question.
Deux difficultés rendent ce taux trompeur si on le prend brut.
La première : être cité n'est pas être mentionné.
Un moteur peut lier votre page sans nommer votre marque, ou nommer votre marque sans la lier — et un comptage qui mélange les deux ne mesure rien de stable. C'est un mécanisme à part entière, traité dans Mémoire de marque ; ce qu'il faut en retenir ici, c'est qu'un taux de présence doit toujours séparer le lien de la mention.
La seconde : le régime de raisonnement change ce que vous mesurez.
Quand le moteur « réfléchit » davantage, il interroge des sources différentes et d'autres marques ressortent. La présence relevée en raisonnement minimal et en raisonnement élevé sont alors deux mesures distinctes, à suivre séparément, jamais à à mettre ensemble.
Reste une question que la présence ignore : ce qui est dit de vous est-il exact ? C'est le deuxième indicateur de Lovett — l'Answer Accuracy Rate, la justesse de votre représentation, évaluée contre un « canon de marque » (votre mission, vos valeurs, les faits que vous publiez) sur des critères de correction factuelle, d'alignement et d'absence d'hallucination. Au-dessus de 85 %, la fondation est saine ; sous 70 %, le risque est réel. Mais la justesse, comme la présence, suppose une condition qu'aucun de ces deux indicateurs ne mesure : que le moteur ait pu vous récupérer. C'est la couche suivante.
La couche retrieval : ce que le moteur récupère de vos pages
C'est la couche dont dépend tout l'output et aussi la plus mesurable des trois. Parce que la récupération qui alimente une réponse IA s'appuie sur les mêmes mécaniques que le search classique — indexation, crawlabilité, recherche vectorielle. Il n'existe pas de couche de récupération IA distincte. La conséquence est encourageante : vous avez déjà les instruments — vos logs, vos données de crawl, votre temps de chargement. La mécanique elle-même, je l'ai détaillée dans Grounding ; la question ici est de la mesurer.
Première mesure : les robots IA atteignent-ils seulement vos pages ? Grounding en posait l'enjeu — sur 700 000 pages analysées par Profound, celles qui échouent à répondre plus de trois fois sur quatre reçoivent dix-huit fois moins de citations, souvent aucune ; et 73 % des sites présentent au moins une barrière technique (Otterly). Le geste de mesure est concret : isolez le trafic des robots IA dans vos logs ou votre CDN, suivez leur taux de crawl réussi et leurs abandons (code 499). Une distinction dit tout, et on le manque souvent : ce sont les robots de récupération qu'il faut surveiller : OAI-SearchBot, ChatGPT-User, PerplexityBot, Perplexity-User, Googlebot pour l'AI Mode —, pas les robots d'entraînement (GPTBot, Google-Extended, CCBot), qui nourrissent une autre couche : la mémoire du modèle. Forrester range ces relevés sous deux indicateurs, le taux de crawl réussi des robots IA et la présence en index vectoriel.

Être atteint ne suffit pas : encore faut-il être exploitable. Et là, un code 200 ne dit pas que le moteur a vu ce qui compte.
Trois résultats à reproduire.
D'abord, votre serveur peut servir un autre HTML aux robots qu'aux humains : un simple test de user-agent — rejouer la page sous l'agent d'un robot IA, comparer le HTML — le révèle, et le contenu qui n'apparaît qu'après un JavaScript que ces robots ne lancent pas tombe dans un fossé de rendu.
Ensuite, une information qui ne vit que dans une image — un prix, une offre, une mention — est de fait invisible dans un flux « récupère et résume », les moteurs lisent le HTML, pas les pixels. Enfin, les agents sont économes, pas curieux : ils résument le visible et s'arrêtent, sans aller chercher le contenu masqué ou une page orpheline. La leçon de mesure tient en une ligne : ce qui compte doit être dans le HTML rendu et visible, faute de quoi vous mesurez une présence que le moteur ne récupère pas.
Reste le point le moins intuitif : être récupéré n'est pas être retenu. De l'ensemble des pages qu'un moteur rassemble pour une réponse — son pool de récupération , il n'en sélectionne qu'une fraction. La métrique qui compte n'est plus le taux de clic mais le taux de sélection (selection rate) : la fréquence à laquelle votre contenu est choisi dans ce pool. C'est la mesure qui succède au CTR — les modèles ne cliquent pas, ils sélectionnent. Forrester la décline en deux indicateurs de récupération : la fréquence de récupération de vos passages, et la confiance du modèle à les retenir. Une nuance, enfin, que les outils peinent encore à saisir : la récupération n'est plus une étape unique. Le moteur éclate votre requête en sous-requêtes — le query fan-out — et vous optimisez pour des questions que vous ne voyez pas. Être récupéré et être fidèlement représenté deviennent alors deux mesures distinctes.
Ces trois relevés — accès, récupérabilité, sélection — partagent un point aspect : ils se lisent dans vos logs. C'est ce qui fait du retrieval la couche la plus pilotable. Mais aucun ne capte ce qui se joue avant la récupération — quand le moteur, sur certaines requêtes, ne cherche pas du tout et répond depuis ce qu'il a déjà retenu de vous. Cette part-là ne laisse aucune trace dans vos logs. C'est elle qu'il reste à mesurer.
La couche latent : ce que le modèle retient de vous
C'est la couche la plus profonde, et la moins visible. Avant d'aller chercher quoi que ce soit sur le web, un modèle porte déjà une représentation de votre marque — des associations formées pendant son entraînement, logées dans sa mémoire paramétrique, la couche que nourrissent précisément les robots d'entraînement écartés du retrieval. Kevin Indig et Dan Petrovic la nomment tous deux le biais primaire : les attributs que le modèle associe à votre marque (« abordable », « durable », « fiable ») avant toute récupération. Cette couche n'est pas anecdotique — ces associations préexistantes pèsent sur ce qui sera cité ensuite. Le mécanisme de la mémoire de marque, je l'ai développé dans Mémoire de marque ; la question ici est différente : comment la mesurer ?
La difficulté est qu'elle ne se lit pas directement — ni dans les poids du modèle, ni dans une réponse ordinaire. Trois approches permettent malgré tout de l'approcher, de la plus simplet à la plus exigeante.
La plus simple ne demande aucun outil, seulement une condition d'observation : interrogez les moteurs là où ils ne cherchent pas — une question sans indice de récence, sur un moteur qui arbitre au cas par cas. Quand un modèle répond avec assurance sans citer de source, il parle de mémoire : cette réponse non ancrée est la couche latente, c'est la base de la mémoire paramétrique.
La deuxième, c'est l'Answer Accuracy Rate de Lovett, l'exactitude de votre représentation mesurée contre un référentiel de marque. Sa vraie portée est ici : ce qui est dit de vous reflète et ce que le modèle retient de vous. Définissez votre référentiel (mission, valeurs, faits), confrontez-y les réponses des moteurs : vous obtenez, indirectement mais concrètement, l'état de la perception latente.
La troisième va plus loin, mais demande des moyens de recherche : le Brand Authority Index de Dan Petrovic. L'idée de départ — sommé de « nommer 100 marques au hasard » 200 000 fois, Gemini ne produit pas une distribution uniforme, et cette non-uniformité révèle quelles marques occupent le plus de place dans sa mémoire. En construisant un graphe d'associations (2,9 millions de marques) et en y appliquant un PageRank personnalisé, Petrovic obtient un score d'ancrage associatif : non pas la popularité, mais la profondeur d'intégration dans la structure du modèle. Une marque jamais citée spontanément peut obtenir un score élevé si elle se trouve à un carrefour dense d'associations.
Trois réserves, à garder en tête avant d'en tirer quoi que ce soit : c'est un seul modèle (Gemini 3 Flash), une méthode non revue par les pairs, et elle repose sur les associations que le modèle déclare sur lui-même — sa vision, pas une vérité de marché. L'ancrage associatif mesure la mémoire d'un modèle, pas la force réelle de votre marque.
La couche latente bouge lentement et se laisse mal saisir, mais elle n'est pas hors de portée : lisible dans ses réponses non ancrées, accessible par l'exactitude, approchable par l'ancrage. Reste qu'on a désormais trois couches, mesurées de trois façons, chacune avec son opacité propre — et les lire ensemble sans se tromper est une discipline en soi.
La discipline qui rend tout ça fiable
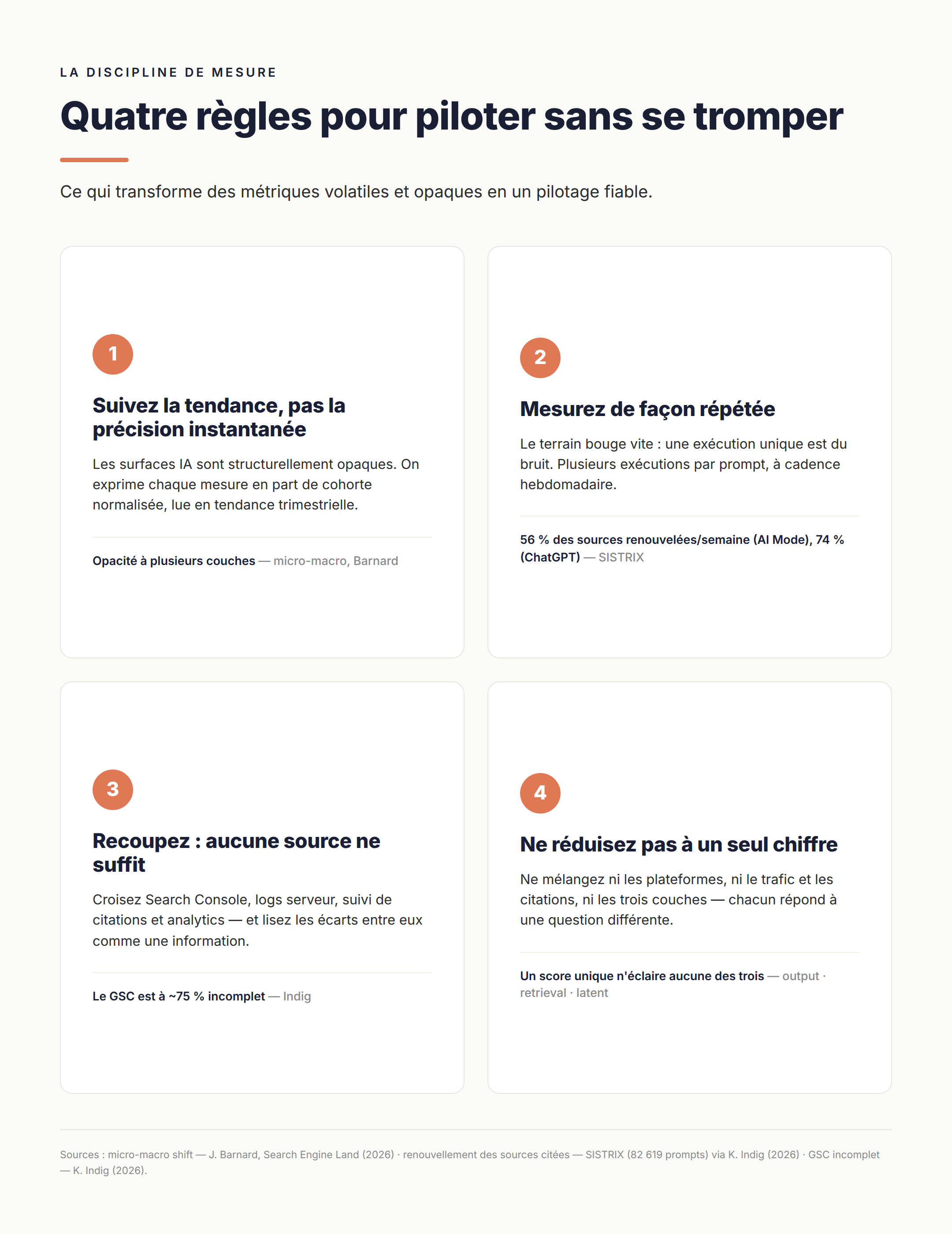
Suivez la tendance, pas la précision instantanée
Les instruments du classement — position exacte, part de voix à l'instant T — ne s'appliquent plus, parce que les IA sont structurellement opaques : on ne voit ni le raisonnement du moteur, ni les options qu'il a écartées, ni ses renoncements silencieux à une affirmation (ce que Jason Barnard nomme l'opacité « BUA », à plusieurs couches). Sa réponse : exprimer chaque mesure en part normalisée d'une cohorte, et lire la tendance trimestrielle plutôt que l'instantané. Demander un relevé mensuel précis dans cet environnement, dit-il, revient à demander à une banque centrale le prix exact d'une baguette ce mois-ci. La contrepartie est la patience : la tendance n'émerge vraiment qu'au bout de quelques trimestres. Le directionnel n'est pas un pis-aller — ici, c'est la seule unité de mesure qui tienne.
Mesurez de façon répétée
Si l'instantané trompe, c'est que le terrain bouge vite. SISTRIX a suivi 82 619 prompts sur 17 semaines : Google AI Mode renouvelle 56 % de ses sources citées chaque semaine, ChatGPT 74 %. À cette dérive, un suivi mensuel revient à consulter son compte en banque une fois par trimestre. Et même à requête fixée, la seule variance d'échantillonnage atteint 10 à 34 % sur des prompts identiques : une exécution unique est du bruit. D'où le protocole posé en amont — plusieurs exécutions par prompt, à cadence hebdomadaire. La présence se lit en fréquence parce que la fréquence est la seule façon de séparer le signal du bruit.
Recoupez : aucune source ne suffit
Même vos références les plus établies sont partielles. Kevin Indig l'a mesuré sur la Search Console : environ 75 % des impressions et 38 % des clics y sont masqués pour raisons de confidentialité. Si la source de référence historique est elle-même aux trois quarts incomplète, aucun tableau de bord ne peut tenir lieu de vérité. La parade est de recouper — Search Console, logs serveur, un outil de suivi de citations, vos statistiques d'audience — et de lire les écarts entre eux comme une information à part entière.
Ne réduisez jamais les couches en un chiffre unique
C'est le fil rouge, généralisé à tout le dispositif. Agréger votre visibilité ChatGPT, Perplexity et Gemini en un « score de visibilité IA » revient à faire la moyenne de votre rang Google et de votre rang Bing : un seul nombre pour des populations qui n'ont rien à voir. Le trafic et les citations tombent dans le même piège — Aleyda Solís a montré qu'ils mesurent deux couches distinctes du parcours, le trafic se concentrant sur les pages d'entrée de marque, les citations sur les pages de découverte et d'évaluation, au point qu'une page d'accueil peut capter l'essentiel du trafic IA et presque aucune citation. Votre rang Google ne prédit pas davantage votre citation par un modèle — l'index apparie une chaîne, le modèle l'interprète, et la même requête y devient deux nombres distincts. Et les trois couches elles-mêmes répondent à trois questions différentes : un score qui les fond n'en éclaire aucune.
Ces quatre règles transforment des métriques volatiles et opaques en quelque chose qui se pilote. Le dispositif n'est pas un tableau de bord qu'on regarde — c'est une discipline qu'on tient. Reste un dernier piège, et c'est le plus insidieux.
Le piège, et l'essentiel
Un risque moins évident : optimiser pour le compteur plutôt que pour ce qu'il mesure. Un AI Signal Rate se gonfle — il suffit de placer sa marque partout — sans que la marque soit pour autant plus utile, plus exacte ou plus légitime. La métrique monte ; la réalité qu'elle était censée capter, non. C'est la loi de Goodhart : dès qu'une mesure devient une cible, elle cesse d'être une bonne mesure. Le travers est déjà installé — une part du secteur, comme l'observe Pedro Dias, a appris à optimiser pour le signal au lieu de produire la qualité que le signal tente de détecter. La mesure ne garde sa valeur qu'en restant un instrument de décision.
C'est pourquoi le dispositif décrit ici n'est pas un tableau de bord de plus. C'est un enchaînement : un jeu de prompts représentatif en entrée, trois couches — output, retrieval, latent — pour savoir ce qui est dit, ce qui est récupérable, ce qui est retenu, et quatre règles pour les lire sans se tromper.
Soyons clairs sur ses limites. Les deux premières couches se mesurent de mieux en mieux : la présence se relève en fréquence, l'éligibilité se lit dans vos logs. La troisième reste une frontière — la perception latente s'approche, elle ne se quantifie pas encore proprement. La mesure de la visibilité IA est jeune ; son but n'est pas un chiffre parfait, mais une tendance défendable sur laquelle appuyer une décision.
Et c'est là tout l'enjeu. On ne mesure pas pour se rassurer devant une courbe, mais pour définir une stratégie : corriger une page qui ne convertit pas, rectifier une représentation inexacte, renforcer une entité absente de la mémoire des modèles. Une mesure qui ne débouche sur aucune action est une mesure de trop. Le reste : les outils, les scores, les tableaux de bord, ne sont que les instruments. Ce qui compte, c'est la décision qu'il permet de prendre.