Markdown : pourquoi c'est le format pivot d'un projet IA
Tous les LLM fonctionnent nativement avec le Markdown. Pourquoi il reste le format pivot quand un LLM entre dans la boucle, et où HTML reprend logiquement la main.
Tous les LLM fonctionnent nativement avec le Markdown. Ce n'est pas un hasard. Les titres, les listes, les tableaux, les blocs de code que Claude ou ChatGPT vous renvoient : c'est sous ce format. Et quand vous leur donnez du contenu à analyser, ils l'analysent plus efficacement quand il est en Markdown plutôt qu'en HTML brut ou en PDF.
Le format reste pourtant peu connu en dehors de cet usage. Comprendre ce format et choisir les bons outils pour l'utiliser : c'est ce qui change la qualité de ce que vous obtenez d'un LLM, et la portabilité de ce que vous produisez ensuite.
Cet article fait le tour du sujet : ce qu'est le Markdown, pourquoi il s'impose comme format pivot quand un LLM entre dans la boucle, où il s'arrête et où le HTML reprend la main, et avec quels outils il s'intègre dans un workflow quotidien — avec Obsidian comme outil de référence.
Le Markdown est le format pivot du travail avec un LLM : économe en tokens, compris nativement en entrée comme en sortie, lisible par un humain comme par une IA. Il n'est pas le bon format pour tout — on convertit ensuite vers HTML, PDF, Word ou deck selon le livrable visé. Mais pour le cœur du travail — prompts, knowledge base, production de texte, configs agent — aucun autre format ne le remplace. Avec Obsidian par-dessus, il devient un véritable environnement de travail.
Sommaire
- Markdown, le format que les LLM "parlent nativement"
- Anatomie du format : ce qu'il faut savoir pour bien l'utiliser
- Markdown vs les autres formats : le bon outil pour le bon contexte
- Quelques règles pour tirer parti du format
- Les outils pour travailler le Markdown au quotidien
- Conclusion
1. Markdown, le format que les LLM "parlent nativement"
Pourquoi les LLM "parlent" Markdown
Les modèles ne choisissent pas leur format de sortie. Ils reproduisent ce qu'ils ont vu pendant leur entraînement. Et ce qu'ils ont vu, c'est des milliards de fichiers Markdown : tous les README de GitHub, les documentations techniques, les articles Wikipedia exportés, les pages de docs des produits SaaS, les transcripts de Stack Overflow.
Un benchmark publié en avril 2026 sur Claude 4.6 (Opus, Sonnet et Haiku) confirme ce point : sur les modèles haut de gamme, la qualité de la réponse est insensible au format passé en entrée — JSON, YAML, Markdown ou texte brut produisent des réponses identiques. Mais le coût en tokens, lui, change. Et c'est là que le Markdown sort en tête.
Le poids économique : la mécanique des tokens
Les LLM facturent au token. Chaque caractère de syntaxe ajouté (balise HTML, virgule JSON, accolade) consomme de la place dans la fenêtre de contexte et coûte à chaque appel API. Sur des contenus équivalents, l'écart entre HTML et Markdown est marqué.

Cloudflare l'a illustré en février 2026 en lançant sa fonctionnalité Markdown for Agents : un article de blog qui consomme 16 180 tokens en HTML n'en consomme plus que 3 150 une fois converti en Markdown. Soit 80% de réduction, sur le même contenu, pour la même information. La différence vient du bruit du HTML : balises, attributs, classes CSS, scripts, navigation, footer — autant de structure visuelle qui n'apporte rien au sens.
Le même bénéfice se vérifie face au JSON : sur un catalogue produit, le Markdown consomme environ 65% de tokens en moins que la version JSON équivalente. C'est un avantage direct, à qualité de réponse égale.
Un format conçu pour la lisibilité humaine, bien avant l'IA
Le Markdown n'a pas été inventé pour les LLM. Il existait bien avant. John Gruber le publie en mars 2004 sur son blog Daring Fireball. L'objectif de départ tient en une phrase de Gruber : "écrire dans un format texte facile à lire et à écrire, qu'on puisse convertir en HTML valide".
L'inspiration vient des conventions de l'email : astérisques pour l'emphase, tirets pour les listes, hiérarchie naturelle via les caractères # — autant d'habitudes qu'on utilisait déjà sans le savoir. La philosophie : un document Markdown doit rester publiable tel quel, en texte brut, sans qu'il ressemble à un fichier balisé.
Vingt ans plus tard, c'est cette même philosophie qui le rend si bien adapté aux LLM. Un format pensé pour qu'un humain le lise sans rendu est, par construction, un format qu'une machine lit aussi sans rendu.
2. Anatomie du format : ce qu'il faut savoir pour bien l'utiliser
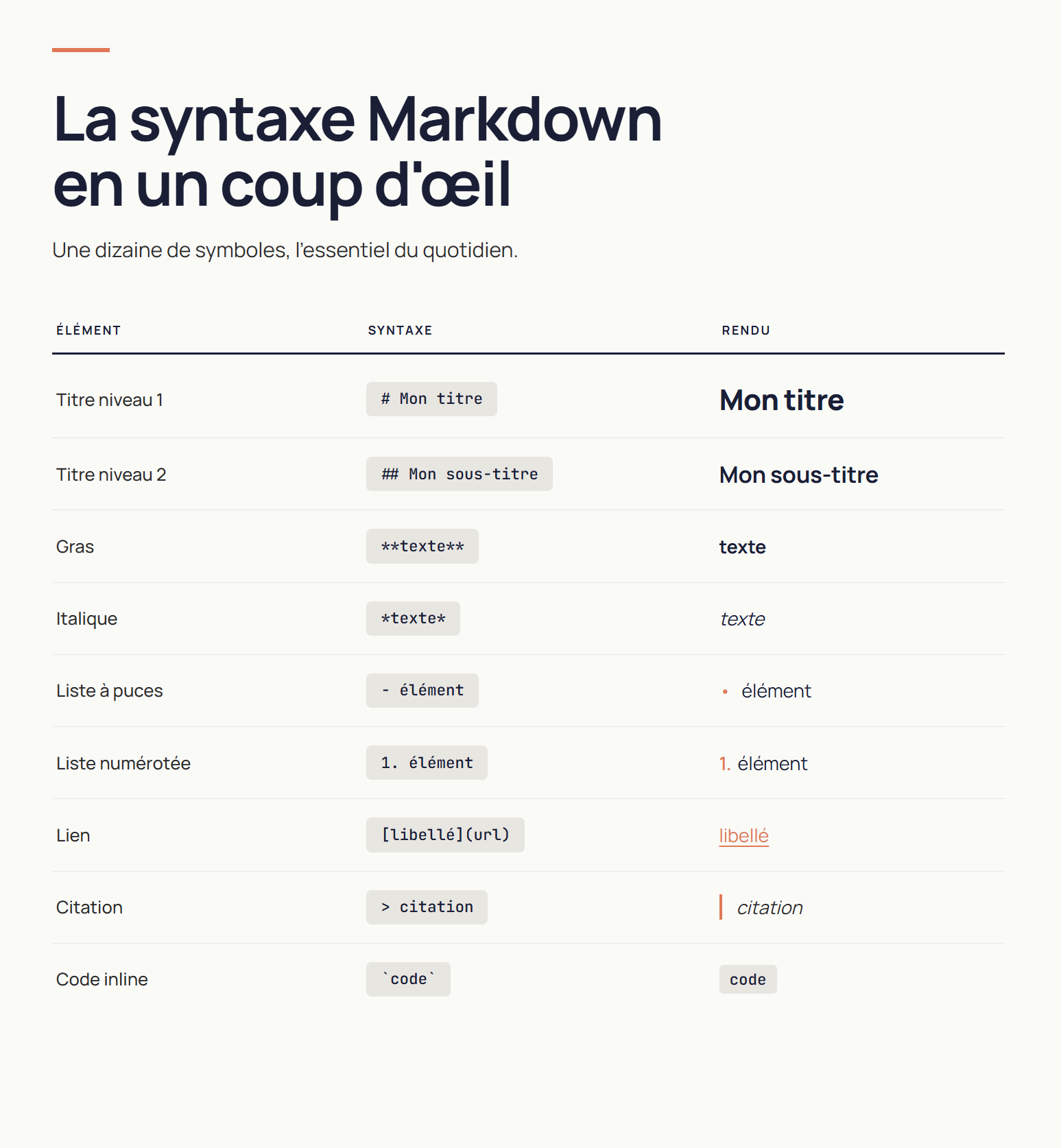
La syntaxe essentielle en un coup d'œil
La particularité du Markdown, c'est qu'on couvre l'essentiel de ce qu'on écrit au quotidien avec une dizaine de symboles. Voici les éléments fondamentaux :
| ÉLÉMENT | SYNTAXE MARKDOWN | RENDU |
|---|---|---|
| Titre niveau 1 | # Mon titre | Grand titre |
| Titre niveau 2 | ## Mon sous-titre | Sous-titre |
| Gras | **texte** | texte |
| Italique | *texte* | texte |
| Liste à puces | - élément | • élément |
| Liste numérotée | 1. élément | 1. élément |
| Lien | [libellé](https://url) | libellé |
| Citation | > citation | citation en bloc |
| Code inline | `code` | code |
La syntaxe s'apprend en quelques minutes. Et contrairement à un format balisé, elle reste lisible même sans rendu : un document Markdown brut se relit comme un texte ordinaire.
Ce que Markdown sait faire de plus
Au-delà des bases, le format gère plusieurs éléments structurants :
- Les tableaux, alignés par barres verticales et tirets. Un tableau Markdown reste lisible en source, sans qu'il soit besoin d'un rendu pour comprendre les données.
- Les listes de tâches (
- [ ]pour vide,- [x]pour cochée), pratiques pour transformer un document en outil de suivi léger. - Les notes de bas de page et les liens automatiques, qui rendent le format adapté à de la rédaction sérieuse.
- Le frontmatter YAML : probablement la fonctionnalité la plus utile dès qu'on accumule plusieurs fichiers. Il s'agit d'un encart de métadonnées placé en tête de fichier, encadré par trois tirets :
---
titre: Plan de contenu Q2
auteur: Romain
date: 2026-04-15
statut: en cours
tags: [contenu, planning]
---Ces métadonnées ne s'affichent pas dans le rendu, mais elles sont exploitables par les outils qui lisent le fichier — pour filtrer, classer, retrouver un document. Une vraie valeur ajoutée dès qu'on travaille sur plusieurs fichiers en parallèle.
Les variantes à connaître
Petit point de vigilance : le Markdown n'est pas une norme unique. Deux variantes structurent l'écosystème.
- CommonMark est la spécification de référence qui standardise le comportement de base. C'est le socle commun adopté par la grande majorité des outils, finalisé en 2014 par un groupe mené notamment par Jeff Atwood (Stack Overflow) et John MacFarlane (auteur de Pandoc).
- GitHub Flavored Markdown (GFM) est l'extension la plus répandue. Elle ajoute par-dessus CommonMark les tableaux, les listes de tâches et quelques autres éléments. C'est, de fait, la variante la mieux supportée partout — y compris par les outils IA, qui ont été entraînés massivement sur du contenu GFM via les README et docs GitHub.
Pour un usage quotidien, retenir le GFM suffit. Les autres dialectes existent (MultiMarkdown, MDX) mais restent réservés à des cas techniques avancés.
3. Markdown vs les autres formats : le bon outil pour le bon contexte
Le choix d'un format dépend du contexte. Word, Google Docs, Notion, PDF, HTML : chaque format à ses propres avantages.
Word et les formats bureautiques : un excellent terrain de destination
Word reste excellent pour ce pour quoi il a été conçu : un document mis en page, un courrier, un contrat, un rapport prêt à signer.
Dans un usage direct avec un LLM, c'est autre chose. Le format .docx est un format compressé qu'on ne peut pas lire dans un simple éditeur de texte. Les LLM peuvent l'ouvrir, mais ils perdent en finesse de structure : la mise en forme parasite la sémantique, les styles ne sont pas toujours interprétés comme des marqueurs de hiérarchie. Word est un format de destination, pas de production. On génère un Word à partir d'un Markdown facilement ; l'inverse fonctionne mal.
Google Docs et Notion : la collaboration en temps réel
Google Docs et Notion sont supérieurs sur un terrain où Markdown est faible : la collaboration en temps réel, les commentaires, l'historique partagé.
Mais la donnée reste dans une plateforme en ligne, pas dans un fichier qu'on exploite. Pour faire entrer un Google Doc dans un workflow avec un LLM, il faut passer par un export, et chaque export dégrade la structure. Notion s'en sort correctement, Google Docs moins, surtout sur les tableaux et les listes imbriquées. Ces deux outils sont excellents en amont ou en aval — pour préparer ou diffuser — mais ils ne sont pas le bon point d'ancrage quand un LLM est dans la boucle.
PDF : le format des sorties figées
Le PDF est excellent pour figer un rendu : un document final, un rapport publié, un fichier archivé. C'est aussi un mauvais format de travail. L'édition est lourde, la structure se dégrade quand on en extrait le contenu, et faire travailler un LLM sur un PDF complexe demande presque toujours une étape de préparation. Comme le Word, c'est une sortie : on le génère depuis un Markdown, on ne l'écrit pas directement.
HTML : le débat qui reprend en 2026
Le HTML a beaucoup fait parler de lui en 2026 face au Markdown. Le débat se clarifie quand on distingue trois usages.
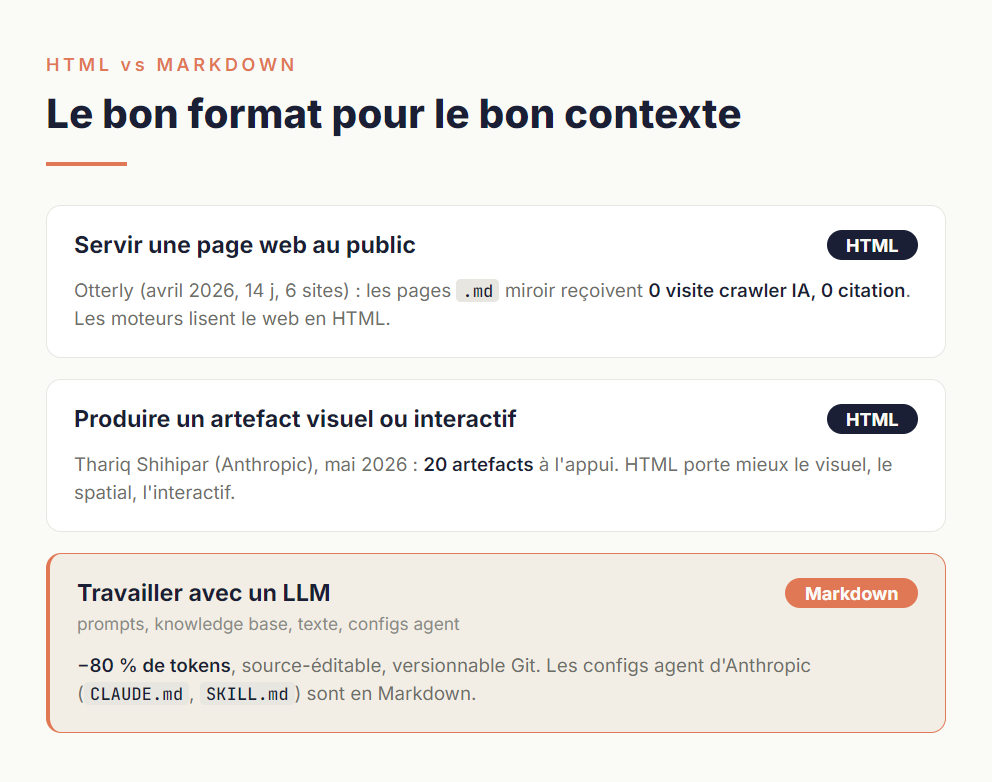
Pour servir une page web au public, HTML reste le standard. Une expérimentation publiée par Otterly en avril 2026, sur 14 jours et 6 sites, le confirme : les pages .md publiées en miroir d'une page HTML reçoivent zéro visite de crawler IA et zéro citation dans les réponses générées. Les moteurs IA lisent le web tel qu'il existe — en HTML, avec ses données structurées et ses balises Open Graph. Le Markdown n'apporte rien dans ce cas.
Pour produire des artefacts visuels et interactifs destinés à un humain, c'est plus nuancé. En mai 2026, Thariq Shihipar (ingénieur sur Claude Code chez Anthropic) publie The Unreasonable Effectiveness of HTML, accompagné de vingt artefacts produits par un agent : pull request annotée, tableau de bord interactif, deck navigable au clavier, éditeur custom. Sa thèse : quand l'output est un livrable visuel, spatial ou interactif, HTML porte mieux que Markdown, qui aplatit tout sur une seule dimension. La position est cohérente avec les cas d'usage qu'il décrit, tous très orientés produit et développement.
Pour le travail avec un LLM — prompts, knowledge base, production de texte, configs agent — Markdown garde un avantage net. Le fichier source reste éditable à la main, il se relit sans rendu, il se versionne dans Git, et il économise massivement en tokens. C'est précisément l'écosystème qu'Anthropic a construit autour de ses propres outils : les fichiers de configuration agent (CLAUDE.md, SKILL.md, AGENTS.md) sont tous en Markdown.
Markdown : le format pivot, et ce que ça veut dire concrètement
Sur les critères qui comptent dès qu'on travaille avec un LLM, le constat est sans appel :
- Texte brut, donc lisible et éditable sans rendu.
- Convertible vers tous les autres formats sans perte de structure : Markdown → Word, PDF, HTML, deck de slides, le tout en une commande ou un export d'éditeur.
- Indépendant de tout logiciel propriétaire : un fichier
.mdreste lisible dans vingt ans, dans n'importe quel éditeur. - Compatibilité native avec tous les LLM, sans conversion intermédiaire.
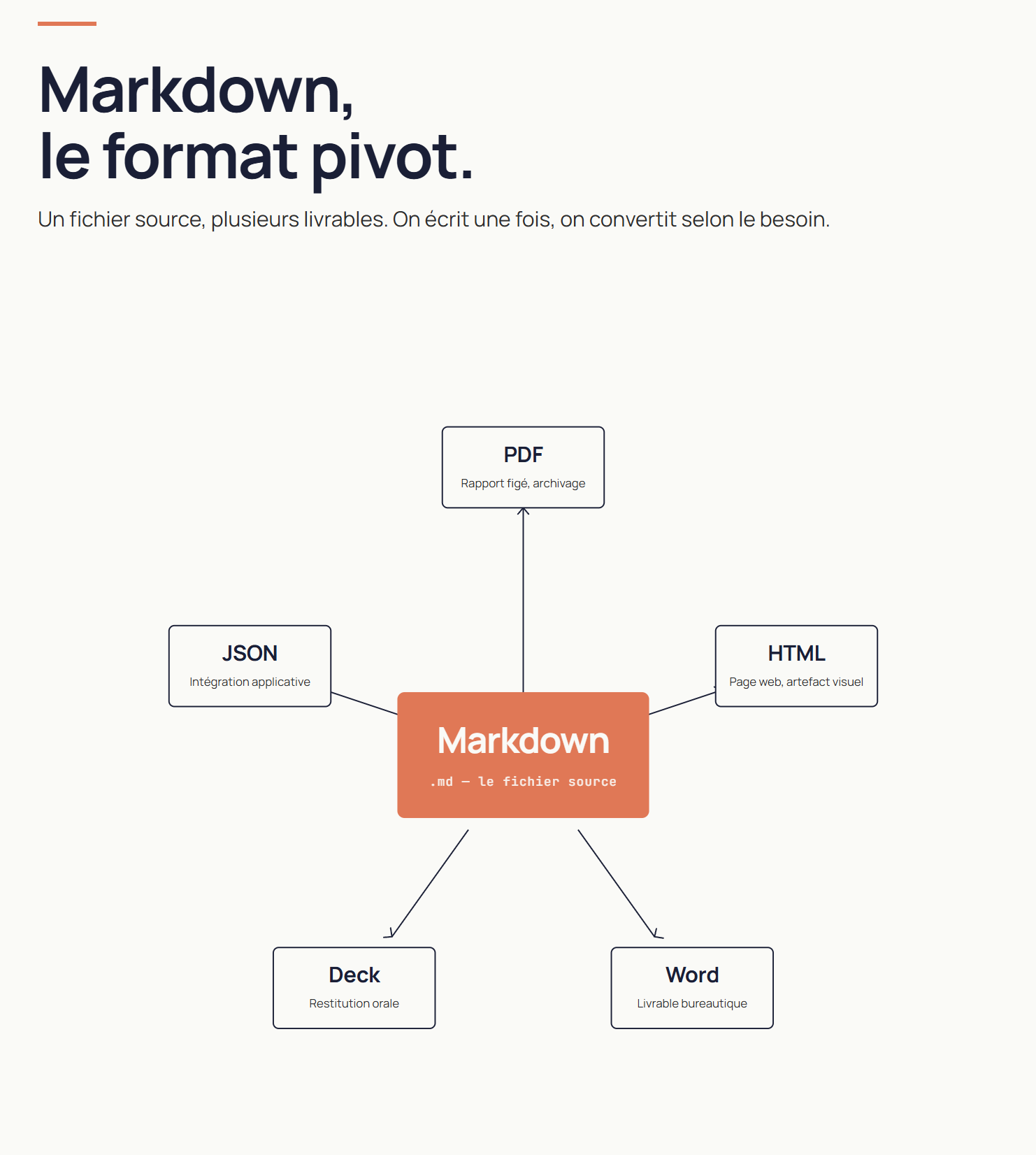
Le rôle de "format pivot" tient à cette propriété : on écrit une fois en Markdown, on convertit vers le format adapté à chaque livraison. Un audit Markdown devient un PDF pour le client final, un deck pour la restitution orale, et reste un Markdown pour les itérations à venir avec un LLM. C'est le centre du dispositif — pas un format universel, mais le point d'origine duquel tout part.
4. Quelques règles pour tirer parti du format
Bien écrire en Markdown ne se résume pas à utiliser la bonne syntaxe. Quelques principes font la différence entre un fichier brouillon et un document propre, qui sera bien lu par vous comme par un LLM.
Structurer ses fichiers proprement
- Un nom de fichier lisible. Pas d'accents, pas d'espaces, des tirets entre les mots, une date quand c'est utile. Un fichier nommé
2026-04-plan-contenu-q2.mdse retrouve et se classe sans effort. - Un seul H1 par document, qui correspond au titre. Des H2 pour les sections principales, des H3 pour les sous-sections. Cette hiérarchie n'est pas juste de la mise en forme : elle aide la lecture humaine, et elle aide encore plus le LLM à comprendre l'organisation du contenu.
- Un frontmatter YAML quand le document a vocation à durer. C'est l'investissement qui se rentabilise le plus vite dès qu'on accumule plusieurs fichiers (titre, date, tags, statut). Les outils qui lisent vos fichiers exploitent ces métadonnées pour filtrer, classer, retrouver.
- Des sections autosuffisantes. Évitez les renvois implicites du type "comme vu plus haut". Chaque section doit pouvoir être lue isolément. C'est utile pour un lecteur qui survole, et c'est précieux pour un LLM qui ne charge pas toujours l'intégralité du document dans son contexte.
Écrire pour être bien lu par un LLM
La structure d'un document Markdown n'est pas qu'une question de lisibilité humaine. Elle conditionne la façon dont les modèles vont découper le contenu en passages exploitables — ce qu'on appelle le chunking. C'est précisément le mécanisme par lequel les pipelines RAG (et plus largement les moteurs de recherche IA) retrouvent et utilisent un fragment de votre contenu pour répondre à une question. Mike King, fondateur d'iPullRank, en a fait l'argument central de son article Misinformation about Chunking en janvier 2026 : bien structurer son contenu, c'est offrir au modèle des unités sémantiques cohérentes qu'il peut isoler, citer et retraiter. Il parle de programmatic legibility — une lisibilité pensée pour qu'un agent IA puisse lire mécaniquement le contenu, en plus du lecteur humain.
Quelques conventions simples vont dans ce sens :
- Des titres explicites. Un H2 doit annoncer clairement son contenu. Évitez les titres allusifs ou trop courts.
- Des listes pour les énumérations de plus de trois éléments, et de la prose pour le raisonnement. Ne transformez pas tout en puces : la prose porte mieux les nuances.
- Le bon élément pour le bon contenu : une citation va dans un blockquote, une donnée comparative dans un tableau. Chaque marqueur a une fonction sémantique que le LLM reconnaît.
- Pas de mise en forme décorative. Le gras systématique, l'italique d'emphase, les majuscules abusives dégradent le signal envoyé au modèle.
- Des métadonnées explicites quand c'est utile : frontmatter, tags. Autant de repères pour un LLM qui explore et analyse vos fichiers.
Ces règles n'ont rien de contraignant. Elles convergent avec ce qui fait un bon document : structuré, clair et autosuffisant.
5. Les outils pour travailler le Markdown au quotidien
Le panorama rapide des outils disponibles
L'écosystème Markdown est vaste, et chaque famille d'outils a sa logique. Voici les grandes options pour situer le paysage :
- Les éditeurs de texte légers comme VS Code ou Sublime Text. Polyvalents, gratuits pour la plupart, ils gèrent Markdown nativement avec coloration et prévisualisation. Bon choix si vous avez déjà un environnement de travail orienté technique.
- Les éditeurs Markdown dédiés comme Typora ou iA Writer. Centrés sur l'écriture, avec rendu en temps réel et interface épurée. Excellents pour la rédaction pure, plus limités quand on accumule beaucoup de fichiers.
- Les éditeurs hybrides de prise de notes comme Obsidian ou Logseq. Ils ne traitent pas le fichier comme un objet isolé, mais proposent un véritable espace de travail : organisation en dossiers, liens entre notes, tags, plugins.
- Les plateformes en ligne comme HackMD ou StackEdit. Pratiques pour collaborer ponctuellement ou éditer un fichier sans rien installer.
Pour un usage régulier et structuré, ce sont les éditeurs hybrides qui font la différence. Et parmi eux, Obsidian sort du lot.
Obsidian : un environnement complet pour vos fichiers Markdown
Obsidian a plusieurs caractéristiques qui le rendent particulièrement adapté à un usage régulier de Markdown.
- Le fichier reste indépendant de l'outil. Un vault Obsidian, c'est un dossier de fichiers
.mdstandards sur votre machine. Aucun format propriétaire, aucune base de données cachée. Si vous désinstallez Obsidian demain, vos fichiers restent intacts, lisibles dans n'importe quel autre éditeur. - Vos données restent chez vous. Les fichiers restent en local, pas sur les serveurs d'une plateforme. Vous conservez l'accès à vos documents et vous choisissez librement votre méthode de synchronisation : iCloud, Dropbox, ou Obsidian Sync.
- Une organisation modulaire. Un vault par thématique, par projet, par domaine. Chaque vault est indépendant, avec sa propre arborescence.
- Un écosystème de plugins très riche qui permet à l'outil d'évoluer avec vos pratiques. La communauté Obsidian est l'une des plus actives du secteur.
Les fonctionnalités qui changent un usage avec un LLM
Quelques fonctionnalités d'Obsidian sont particulièrement utiles quand un LLM entre dans la boucle :
- Le graph view et les liens internes matérialisent visuellement les connexions entre vos documents. Vous écrivez
[[nom-du-fichier]]dans une note, et Obsidian crée un lien navigable. Au fil du temps, votre vault devient un réseau de connaissances explorable. - Les properties et les Bases structurent vos contenus au-delà du simple texte. Les properties ajoutent des métadonnées à chaque note (date, statut, tags, audience), et les Bases — un plugin officiel de l'équipe Obsidian — produisent des vues filtrables proches d'un tableau de base de données. C'est exactement la mécanique qu'utilise Marco Giordano (Seotistics) pour piloter un calendrier éditorial et faire travailler Claude dessus.
- Les templates permettent de standardiser les formats récurrents. À chaque nouveau document, vous partez d'une structure optimisée — utile pour les briefs, les notes de réunion, les fiches client.
- Les serveurs MCP connectent Obsidian directement à Claude (et à d'autres LLM compatibles). Une fois configuré, le LLM peut lire votre vault, créer ou mettre à jour des notes, exécuter des requêtes sur vos métadonnées. C'est le pont qui transforme votre base personnelle en interlocuteur direct de votre LLM.
Pour les usages les plus avancés, un pattern émerge en 2026 sous l'impulsion d'Andrej Karpathy : le LLM Wiki, une architecture de vault où un agent IA transforme en continu les sources brutes (articles, transcripts, notes) en pages structurées et interconnectées. Le pattern dépasse le cadre de cet article — j'y reviendrai dans une publication dédiée à Obsidian.
Obsidian n'est pas une base de données
L'engouement récent autour d'Obsidian comme "second cerveau IA" a brouillé une distinction importante : un vault Markdown n'est pas une base de données structurée. Au-delà de quelques milliers de notes, la lecture par un LLM commence à coûter cher en tokens, les requêtes complexes deviennent difficiles, et l'absence de schéma rend la recherche fine peu fiable. Jonathan Edwards en a fait une critique argumentée en mars 2026.
Le point est juste — et il ne change rien à l'intérêt d'Obsidian pour notre sujet. Pour la production de contenu, la knowledge base personnelle ou les briefs projet, un vault Markdown reste un outil particulièrement bien calibré : assez structuré pour qu'un LLM s'y oriente, assez simple pour qu'un humain y écrive sans friction. Quand le besoin bascule vers du stockage de données structurées à grande échelle, on change d'outil. Mais ce n'est pas le sujet ici.
6. Conclusion
Le Markdown est le format pivot pour le cœur du travail avec un LLM — prompts, knowledge base, production de texte, configs agent — aucun autre format ne tient. Pour les livrables visuels et interactifs destinés à un humain, HTML reprend logiquement la main. Pour le stockage de données structurées à grande échelle, on bascule vers une vraie base de données. C'est aussi pour ça qu'il s'est progressivement installé au centre de ma pratique.