Knowledge base et LLM : la méthode complète
Une knowledge base n'est pas un dossier de fichiers, c'est la configuration locale d'un système de récupération ancrée. Méthode complète, mécanique, et principes d'écriture.
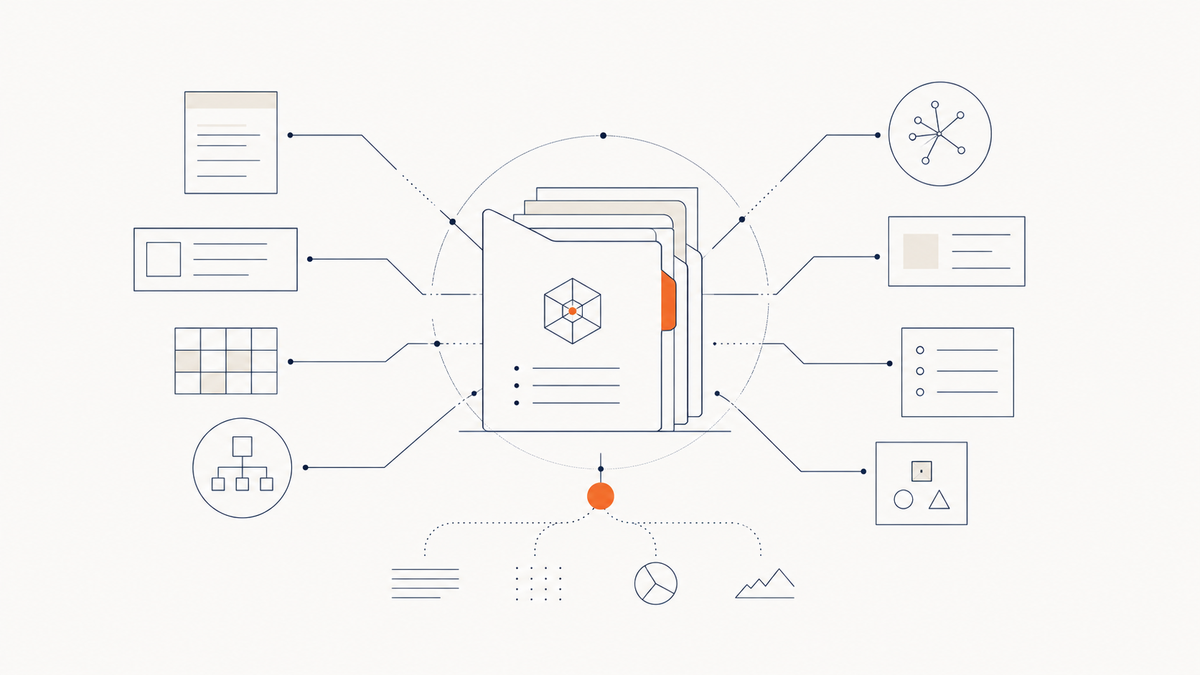
Travailler avec un LLM sans knowledge base, c'est passer une partie de chaque conversation à redonner le même contexte : qui vous êtes, à qui vous parlez, ce qui a déjà été tranché, ce qui doit être respecté. Cette re-contextualisation pèse, à la fois sur l'attention que vous y consacrez et sur la qualité des réponses obtenues.
La knowledge base répond à ce problème, mais elle fait plus que gagner du temps. Quand elle est bien construite, elle optimise la façon dont le modèle interprète à votre contexte. C'est un cas particulier d'une mécanique générale que j'ai détaillée dans l'article sur l'AI Search — la récupération ancrée, ce mécanisme déterministe par lequel un modèle consulte d'abord un corpus indexé avant de générer sa réponse. Ce que les moteurs IA industrialisent à l'échelle du web, vous le configurez à la main, localement, pour vos usages récurrents.
Cet article reprend la méthode que j'utilise quotidiennement. Vous y trouverez ce qu'est précisément une knowledge base, ce qui se passe quand le modèle l'analyse, la structure type que je préconise en neuf documents complémentaires, les principes de formatage qui rendent ces documents exploitables, et la pratique qui fait que la méthode tient dans le temps.
Une knowledge base n'est pas un dossier de fichiers. C'est la configuration locale d'un système de récupération ancrée — le mécanisme déterministe par lequel un LLM va chercher dans un corpus indexé avant de répondre.Sa qualité repose sur trois dimensions : la structure documentaire (qui et quoi sont décrits), la lisibilité par le modèle (qui détermine ce que le LLM retrouve réellement), la maintenance (qui détermine ce qui reste pertinent dans le temps).Le cœur de la méthode : neuf documents complémentaires, des règles de formatage qui font la différence, une discipline de mise à jour. L'ensemble fonctionne comme un système, pas comme une checklist.
1. Qu'est-ce qu'une knowledge base, mécaniquement
1.1 Un cas particulier d'une mécanique générale
Pour comprendre ce qu'est une knowledge base, il faut commencer par comprendre comment un LLM accède à de l'information externe au moment où il vous répond.
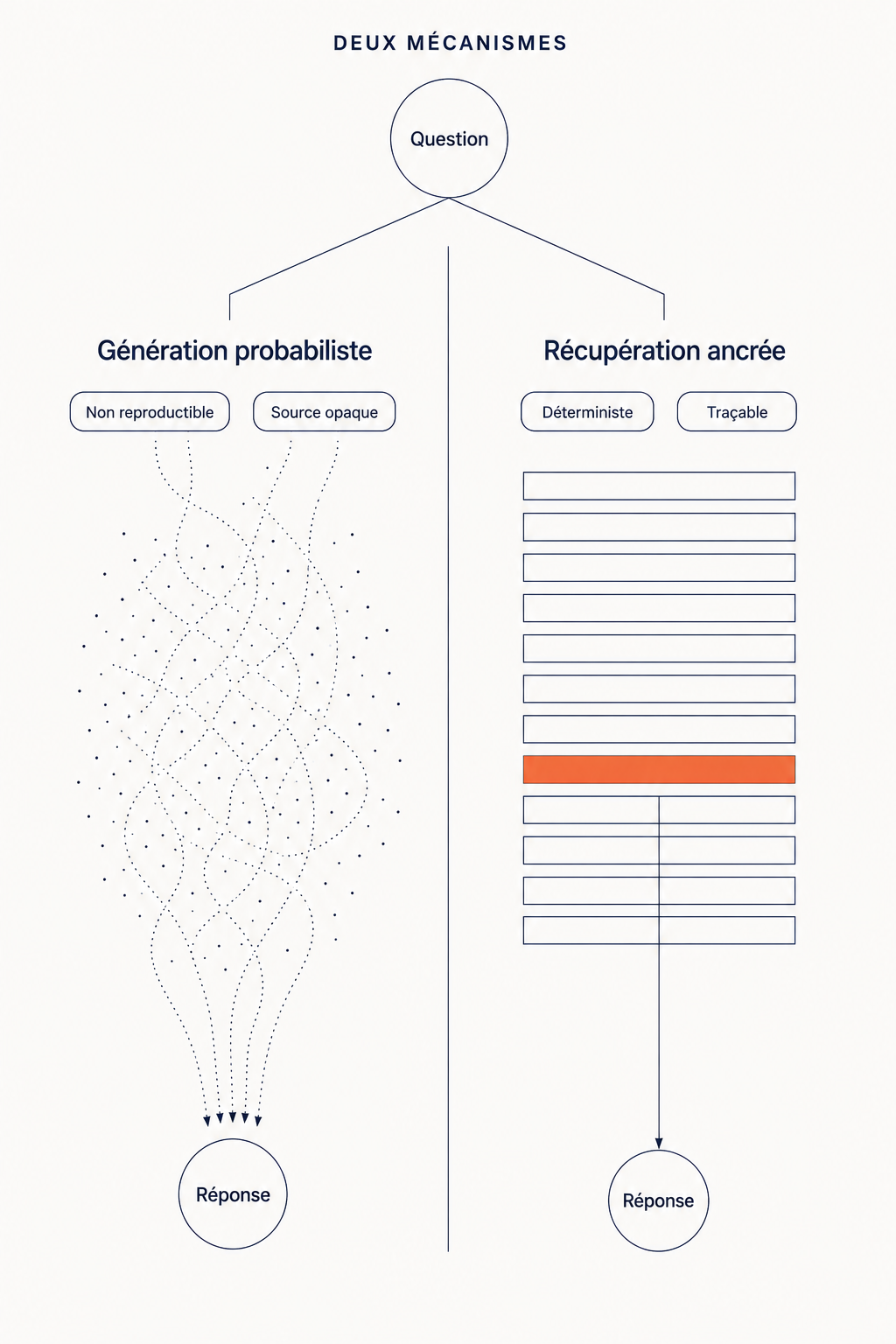
Un modèle de langage a deux modes de fonctionnement, fondamentalement différents, comme je l'ai détaillé dans l'article sur l'AI Search. Le premier mode est la génération probabiliste (probabilistic generation) : à partir des données absorbées pendant son entraînement, le modèle prédit les mots les plus probables, séquence après séquence. C'est ce qui produit ces réponses mais non reproductibles, où le modèle paraît tirer des connaissances sans pouvoir préciser d'où elles viennent. Le second mode est la récupération ancrée (grounded retrieval) : avant de générer, le modèle consulte un corpus indexé, en extrait les passages les plus pertinents, et s'appuie dessus pour formuler sa réponse. C'est un mécanisme déterministe, mesurable, influençable par la qualité de ce qu'on lui donne à indexer.
Une knowledge base relève strictement du second mécanisme. Quand vous créez un Projet sur Claude, un Projet sur ChatGPT, ou un Gem sur Gemini, vous configurez un système de récupération ancrée locale : un corpus dédié, un dispositif d'indexation avec une logique de consultation à chaque requête. Le modèle ne se contente pas de lire votre knowledge base, il y opère un retrieval ciblé à partir de votre question, il identifie les passages les plus pertinents de votre corpus et les utilise dans son contexte avant de générer une réponse.
Pedro Dias formule la même idée à une autre échelle dans son article fondateur Your AI Strategy Isn't a Strategy : la couche de récupération qui sous-tend les AI Overviews et les chatbots fonctionne mécaniquement sur les mêmes principes que la recherche traditionnelle. Indexation, recherche vectorielle, scoring de pertinence — c'est de la même physique. Une knowledge base, c'est cette physique-là, appliquée à votre projet
1.2 Un RAG pipeline configuré localement
Cette mécanique n'est pas spécifique à votre projet. C'est l'un des contextes de récupération qui structurent aujourd'hui le web pour les IA.
Pedro Dias distingue, dans ses analyses sur l'architecture du retrieval, quatre retrieval contexts auxquels un contenu peut être confronté en 2026 :
- Les crawlers classiques, qui indexent pour les moteurs de recherche traditionnels (Googlebot, Bingbot).
- Les RAG pipelines, qui consultent un corpus pour répondre à une question en temps réel — c'est le mécanisme de l'AI Overview, de Chat GPT, de Perplexity, qui citent leurs sources.
- Les agent browsers, qui naviguent et lisent activement le web pour le compte d'un utilisateur.
- Les training crawlers, qui collectent du contenu pour l'absorber dans les jeux de données d'entraînement (GPTBot, Google-Extended, etc.).
Une knowledge base dans un projet Claude appartient à la deuxième catégorie : c'est un RAG pipeline configuré localement— autrement dit, une chaîne de traitement qui organise la récupération avant la génération, et que vous maitrisez entièrement. Vous délimitez le corpus (les fichiers que vous partagez), vous définissez le comportement à adopter (les instructions système), et le système organise le retrieval automatiquement à chaque interaction. La différence avec les RAG pipelines à l'échelle du web tient à l'organisation que avez défini : ce qui est indexé, comment c'est structuré, ce qui prime sur quoi.
Cette précision n'est pas un détail. Elle change la manière de concevoir la knowledge base. Un dossier de documents qu'on consulte de temps en temps fonctionne par accumulation : on y empile des fichiers en se disant qu'on les retrouvera au besoin. Un RAG pipeline fonctionne par éligibilité : ce qui est récupéré n'est pas ce qui est important, c'est ce qui est lisible, identifiable, isolable au moment où le modèle en a besoin. C'est un changement de perspective décisif pour la suite.
1.3 Pourquoi c'est un actif différencié
Si on accepte que la knowledge base est un mécanisme de récupération, une question stratégique se pose : que mettre dedans ?
Pedro Dias propose une grille qui s'applique particulièrement bien ici, dans son article Publishing Everything Is a Terrible Business Strategy. Il rappelle que, dans une économie où le contenu générique est désormais produit à coût quasi nul par les modèles, trois catégories de production restent précieuses :
- La recherche qui requiert une synthèse à partir de sources non publiques — conversations clients, données propriétaires, investigations originales.
- L'expertise qui se compose — la spécialisation profonde qui se construit sur elle-même, qu'un modèle généraliste ne peut pas répliquer.
- Les perspectives qui portent du risque et de la responsabilité — les positions qui engagent un jugement, qui supposent un engagement personnel, et qu'on ne peut pas générer en série.
Ces trois catégories décrivent exactement ce qui doit constituer le cœur d'une knowledge base. Une knowledge base, c'est l'inverse du blog ouvert au public : c'est l'endroit où vous concentrez précisément ce que vous ne publiez pas, parce que c'est ce qui fait votre différence opérationnelle. Vos méthodes affinées, vos arbitrages internes, vos formulations validées, vos données sectorielles non diffusables, votre lecture du marché. La valeur de la knowledge base est strictement proportionnelle à la valeur de ce que vous y mettez — et donc à votre capacité à y placer ce qui ne se trouve nulle part ailleurs.
Cette dimension change aussi la façon de penser la maintenance. Une knowledge base ne se construit pas à l'avance puis se laisse en place. Elle vit, s'enrichit après chaque session, capitalise sur les apprentissages, intègre les décisions au fur et à mesure qu'elles sont rendues. .
1.4 Ce que cette mécanique change dans la pratique
Concrètement, ce que vous gagnez en configurant une knowledge base bien construite tient en trois choses :
- La fin de la re-contextualisation. Les conversations démarrent directement sur le fond, sans avoir à rappeler à chaque ouverture votre rôle, votre cible, votre ton, vos contraintes.
- Des réponses calibrées sur votre contexte, pas sur un contexte générique. Le modèle ne raisonne plus sur un projet abstrait, il raisonne sur le vôtre.
- Une capitalisation cumulative dans le temps. Les apprentissages d'une session servent à la suivante, les décisions rendues ne sont pas à reprendre, les formulations validées sont conservées.
Ce que vous configurez n'est pas un raccourci, c'est un référentiel structuré qui calibre durablement la qualité du travail produit avec le modèle. Et c'est précisément parce que ce référentiel est consulté techniquement, par un mécanisme de retrieval, que la façon dont il est rédigé compte autant. C'est l'objet de la section suivante.
2. La mécanique du retrieval
Maintenant qu'on a posé qu'une knowledge base est un système de récupération ancrée, il reste à comprendre ce qui se passe techniquement quand le modèle la consulte. Le retrieval — c'est ainsi qu'on désigne l'opération par laquelle le système identifie et charge les fragments pertinents avant de répondre ce qui détermine directement la façon dont vos documents doivent être conçus.
2.1 Chunking et passages : ce que voit votre LLM
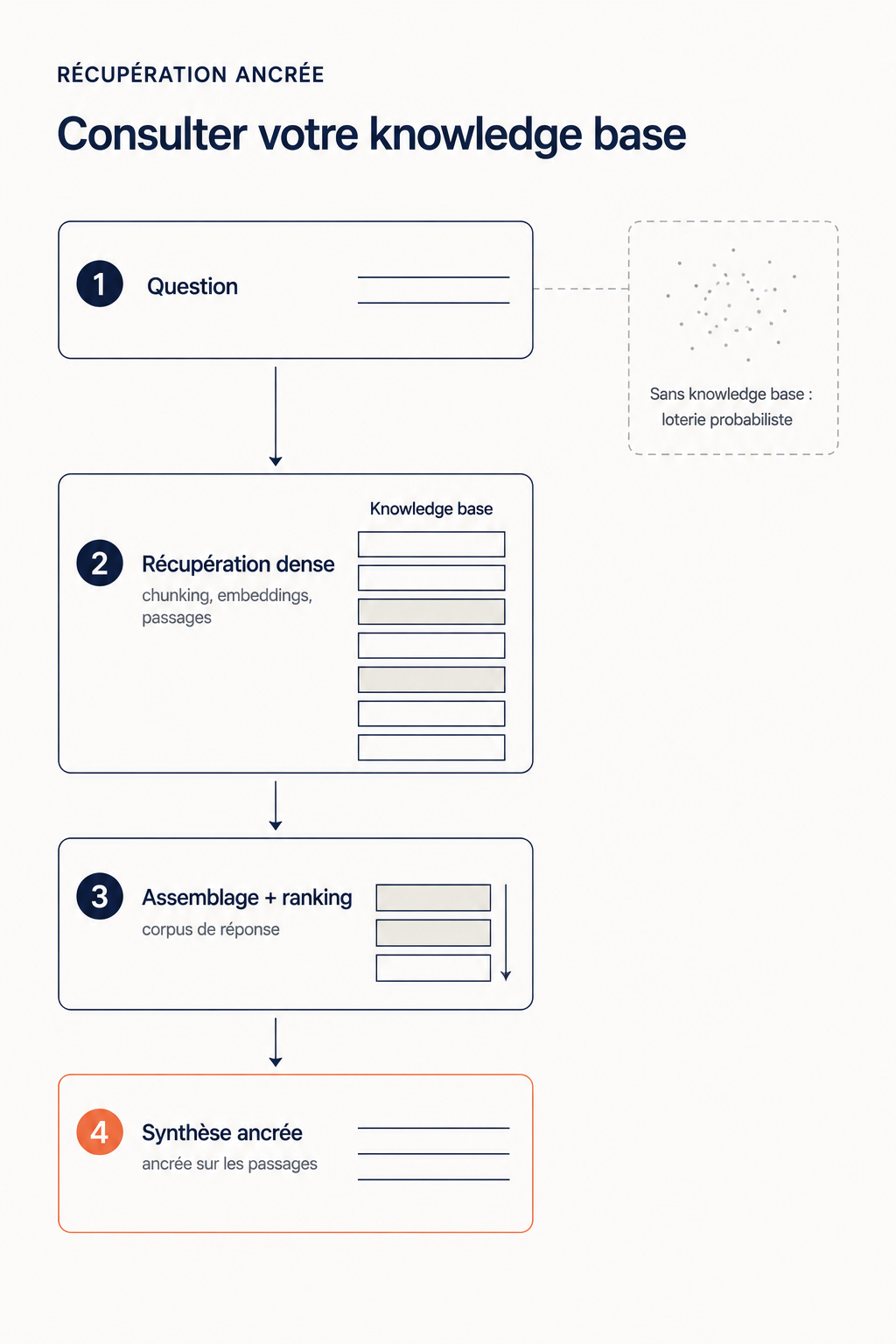
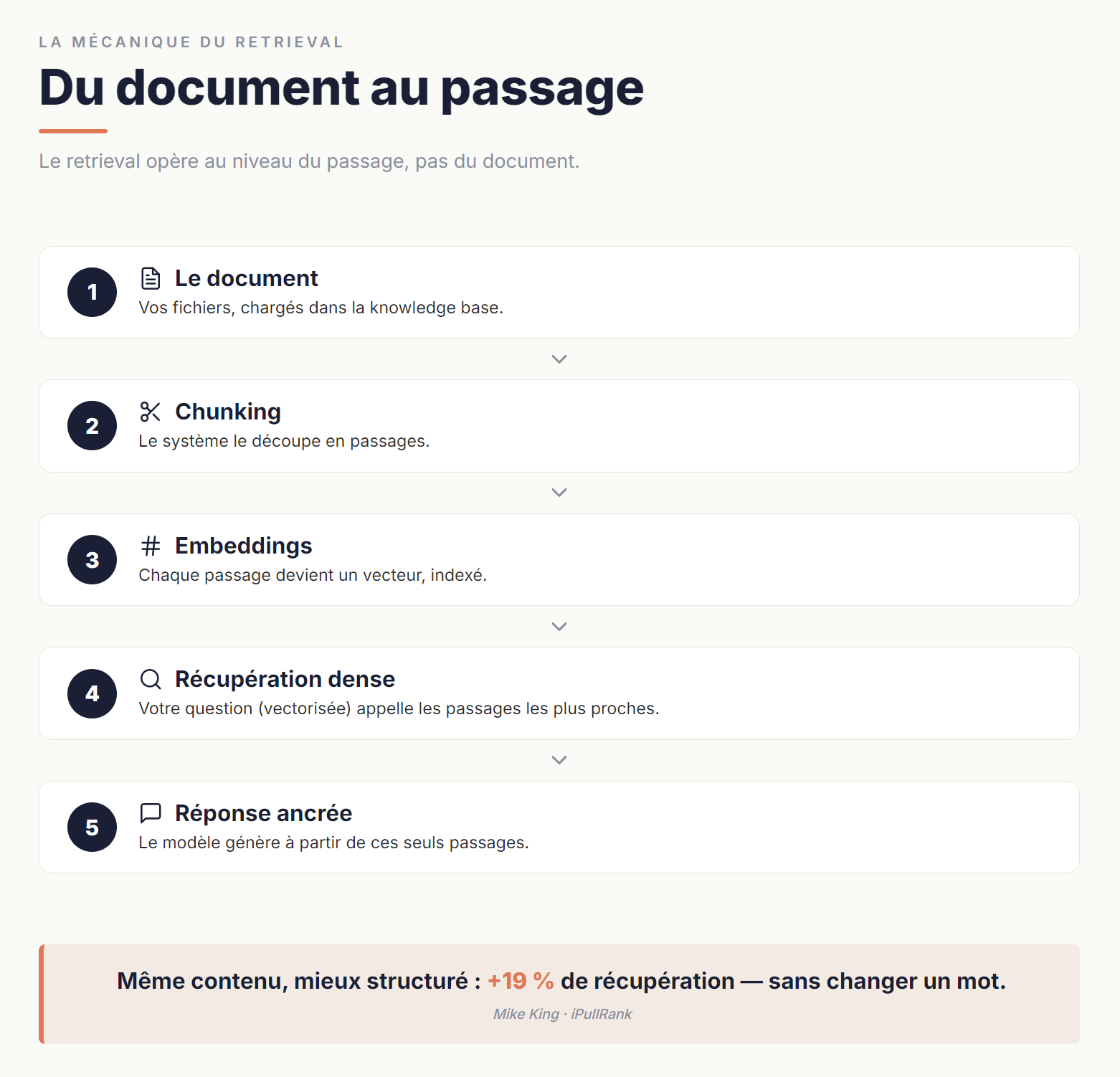
Quand vous chargez un document dans une knowledge base, le système ne le stocke pas tel quel. Il le découpe en passages — c'est ce qu'on appelle le chunking. Chacun de ces passages est ensuite transformé en représentation vectorielle (un embedding) et indexé. À chaque fois que vous posez une question, votre requête est elle-même transformée en vecteur, puis le système recherche les passages dont l'embedding est le plus proche de celui de votre question. C'est la récupération dense (dense retrieval) : la pertinence n'est plus jugée au niveau du document, elle est jugée au niveau du passage.
Cette mécanique est documentée dans la recherche scientifique et dans les brevets Google qui structurent les moteurs IA actuels. Mike King décrit le pipeline complet dans How AI Mode Works : la requête est interprétée, déclinée en sous-requêtes synthétiques, le système opère un retrieval dense au niveau du passage, assemble un corpus dédié à la réponse, puis ordonne les passages avant la synthèse finale. À chaque étape, ce sont les passages, pas les documents, qui sont l'unité de traitement.
Une conséquence est immédiate : un passage qui ne tient pas tout seul n'est pas correctement retrouvé. S'il dépend d'un contexte présent ailleurs dans le document, son embedding est dilué par cette dépendance, et son score de similarité avec votre question est mécaniquement plus faible. Mike King en fait la démonstration empirique dans Misinformation about Chunking : un paragraphe qui traite simultanément de deux sujets obtient un score de similarité de 0,541 sur le premier sujet et 0,620 sur le second. Quand on découpe ce paragraphe en deux paragraphes monothématiques, sans changer un seul mot, le score sur le premier sujet monte à 0,645, soit une amélioration de 19,24 %. L'ajout d'un titre sur le second paragraphe ajoute encore 17,54 % de similarité.
Autrement dit : la simple structuration d'un document — sans changer son contenu — modifie significativement ce que le modèle est capable d'en extraire. Mike King résume le principe en une formule : "You cannot compress a mess without losing the message."
2.2 L'éligibilité avant la pertinence
Cette mécanique inverse l'ordre des priorités auquel on est habitué.
Dans une logique éditoriale classique, un document est jugé d'abord sur sa pertinence : est-ce que c'est bien écrit, est-ce que ça répond à la question, est-ce que l'angle est bon. Dans une logique de récupération ancrée, un passage doit d'abord être éligible — c'est-à-dire identifiable et autosuffisant — pour être candidat à la pertinence. Mike King formule cette inversion de manière mémorable : "Eligibility is the new ranking." Tant qu'un passage n'est pas éligible, le système ne le retrouvera pas.
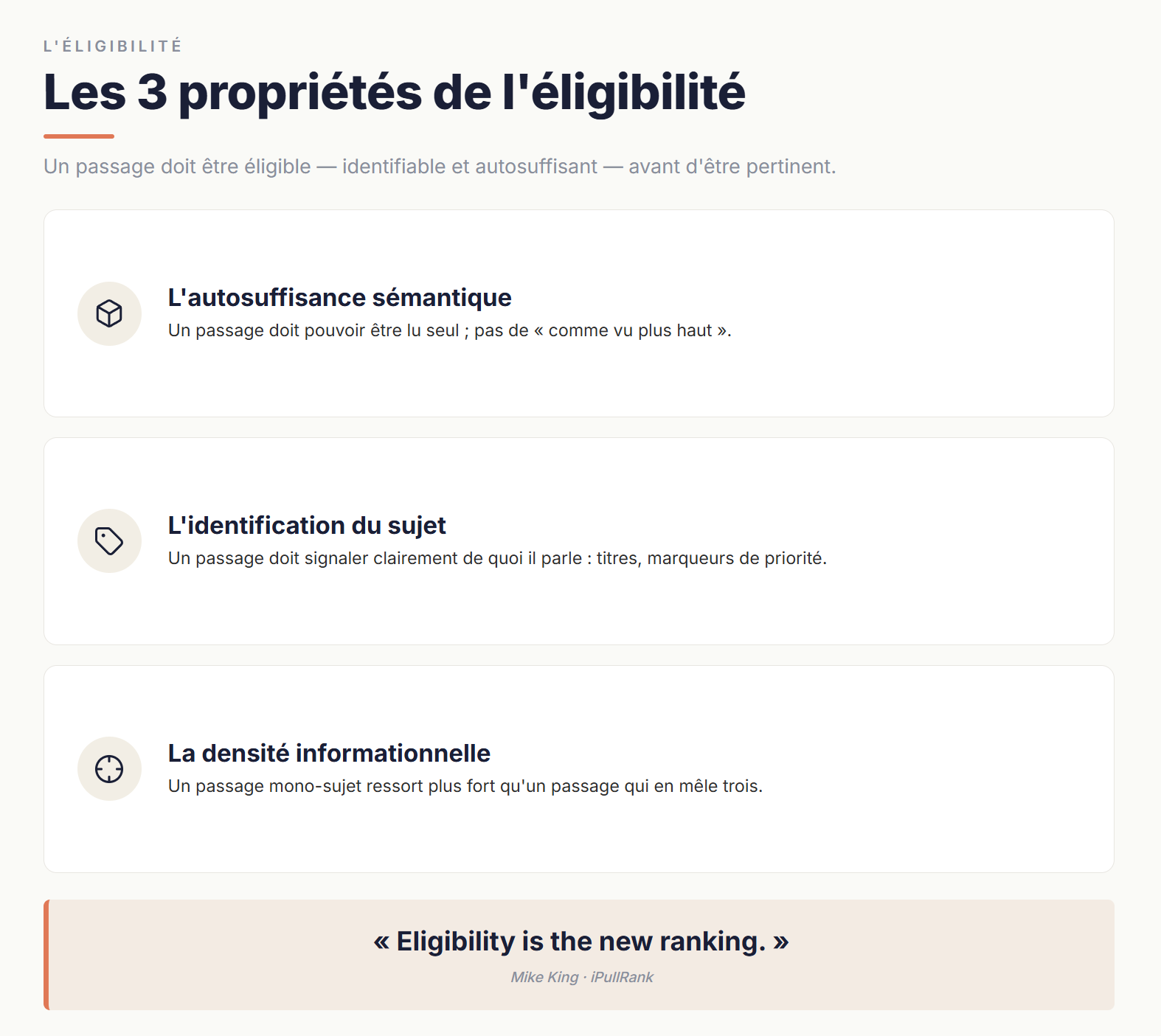
L'éligibilité repose sur trois propriétés concrètes :
- L'autosuffisance sémantique du passage. Un passage doit pouvoir être lu seul. S'il commence par "Comme on l'a vu plus haut" ou "Pour les raisons évoquées précédemment", son sens dépend d'un contexte qui ne sera pas chargé avec lui. Le passage devient ce que Mike King appelle de la noisy data — du bruit, pas du signal exploitable.
- L'identification explicite du sujet traité. Un passage doit clairement signaler de quoi il parle. Une hiérarchie de titres bien posée, un titre de section explicite, voire un marqueur de priorité quand c'est pertinent, ne sont pas des éléments de style : ils sont des aides directes à l'identification du passage par le système.
- La densité informationnelle locale. Un passage qui traite simultanément de trois sujets dilue son propre score sur chacun. Un passage qui traite d'un sujet avec densité ressort plus fort. C'est exactement ce que démontre l'expérience citée plus haut.
Ces trois propriétés structurent toute la section sur les principes de formatage qui va suivre. Elles expliquent pourquoi la règle des phrases auto-portantes, la hiérarchie Hn rigoureuse et les encarts de priorité explicites fonctionnent : ce ne sont pas des conventions cosmétiques, ce sont des signaux d'éligibilité qui rendent vos passages identifiables au moment où le modèle en a besoin.
Mike King propose une formulation qui condense cette logique : il s'agit de faire de votre contenu une API of meaning, une interface où chaque passage est un point d'accès propre, lisible, isolable. Ce qu'on cherche à produire n'est plus un texte qui se lit linéairement, c'est une matière dont chaque fragment reste exploitable indépendamment du tout.
2.3 Pourquoi le Markdown s'impose
Cette mécanique d'éligibilité explique aussi pourquoi le Markdown est devenu le format de référence pour les knowledge bases. Quand un document est structuré en Markdown, sa hiérarchie est techniquement signalée — chaque titre est identifiable, chaque liste est reconnue comme telle, chaque bloc de citation est une mise en relief.
Le système peut alors utiliser ces marqueurs structurels comme indices de découpage : il sait où couper, il sait quel passage est subordonné à quel autre, il sait quelles sections sont mises en avant. Un document Markdown bien rédigé donne au système une carte de lecture explicite, là où un document non structuré le laisse deviner.
Je ne reviens pas en détail sur ce format ici — j'y consacre un article entier. L'essentiel est de retenir que le choix du Markdown n'est pas uniquement une question de facilité : c'est une optimisation directe de l'éligibilité de votre knowledge base.
3. La structure type d'une knowledge base
La structure que je présente ici est celle que j'utilise au quotidien, affinée au fil de la pratique. Elle s'organise en neuf documents complémentaires. Chacun a un rôle précis, et l'ensemble fonctionne comme un système — chaque document apporte une couche d'information que les autres présupposent.
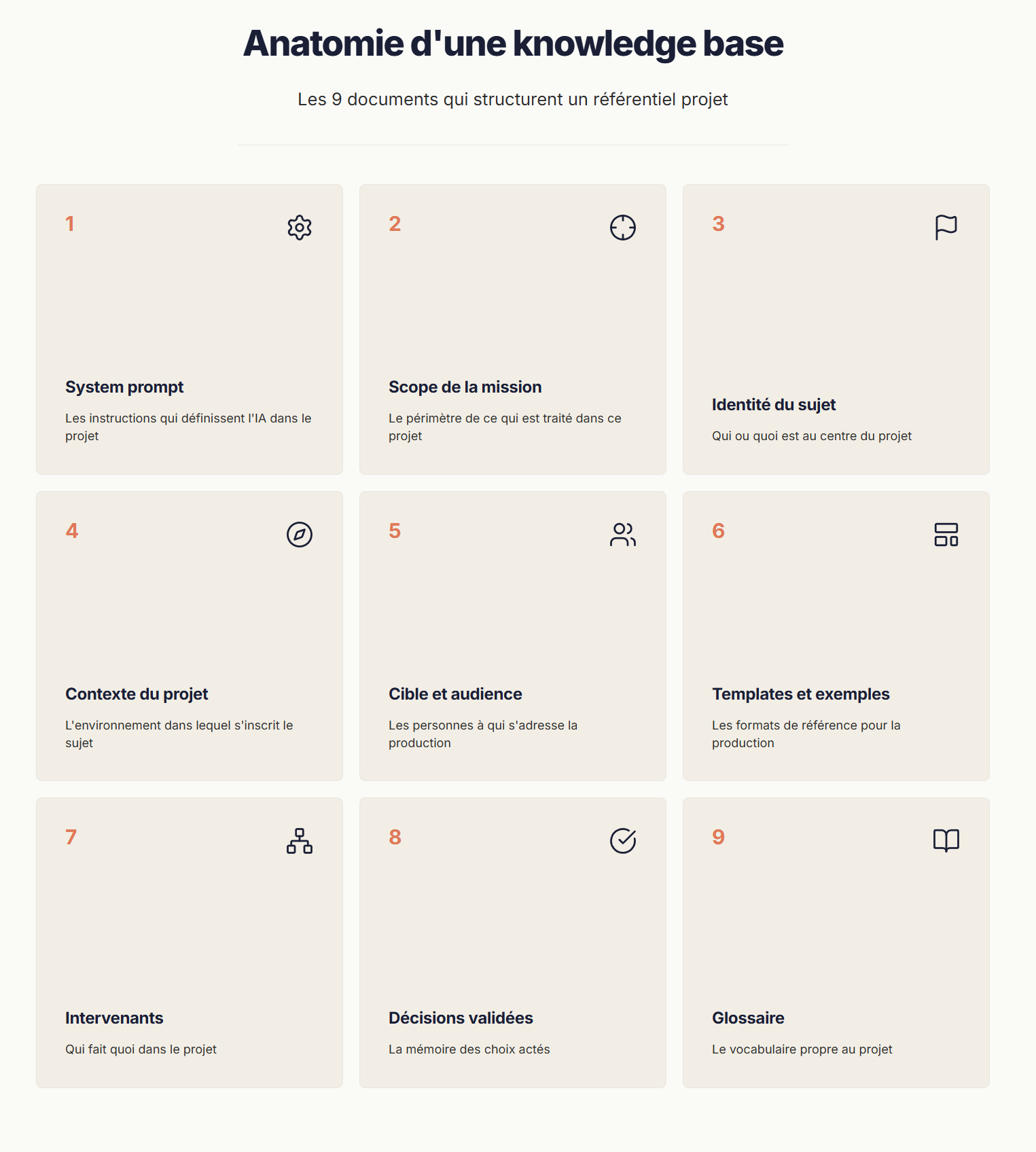
3.1 Les neuf documents qui composent la knowledge base
1. Le system prompt — les instructions qui définissent le modèle dans le projet
C'est le document de base. Il définit comment le modèle se comporte, qui il incarne, ce qu'il fait toujours, ce qu'il ne fait jamais, et le format de réponse attendu. C'est aussi celui qui est lu en priorité par le modèle, et qui conditionne tout le reste.
2. Le scope de la mission — le périmètre de ce qui est traité
Ce document cadre ce sur quoi on travaille — et ce sur quoi on ne travaille pas. Il pose les objectifs, les livrables attendus, les jalons, les contraintes. Sans lui, le modèle peut déborder ou manquer de cible.
3. L'identité du sujet — qui ou quoi est au centre du projet
"Le sujet" peut être une marque, une activité, un domaine d'expertise, un produit, ou toute entité qu'on cherche à mettre en avant. Ce document décrit son identité, son positionnement, ses spécificités, son histoire pertinente.
4. Le contexte du projet — l'environnement dans lequel s'inscrit le sujet
C'est la couche externe : le marché, les concurrents, les tendances, les références sectorielles, les opportunités identifiées.
5. La cible et l'audience — les personnes à qui s'adresse la production
Ce document décrit la cible : profils, motivations, freins, vocabulaire utilisé, canaux par lesquels elle est atteinte. Il permet au modèle de calibrer le registre et les arguments selon l'audience visée.
6. Les templates et exemples valides — les formats de référence pour la production
C'est la bibliothèque opérationnelle. On y trouve les structures types pour chaque format récurrent (notes, briefs, emails, posts, analyses), accompagnées d'exemples concrets validés. La section qui ancre le plus directement la cohérence de la production.
7. Les intervenants du projet — qui fait quoi
Ce document recense les contacts clés, leur rôle, ce qu'il faut savoir pour communiquer efficacement avec chacun. Il permet au modèle de calibrer ses productions selon le destinataire et de tenir compte des sensibilités relationnelles.
8. Les décisions validées — la trace des choix actés
C'est la mémoire du projet. À chaque décision rendue — orientation stratégique, choix éditorial, refus explicite — on l'archive ici. Le modèle s'y réfère avant toute production pour respecter ce qui a déjà été acté, sans avoir à redemander.
9. Le glossaire — le vocabulaire propre au projet
Termes métier, acronymes, noms internes, conventions de nommage. C'est le document qui évite les contresens et qui permet au modèle de parler juste du premier coup, sans demander ce que signifie un terme spécifique.
3.2 Pourquoi neuf documents et pas un seul
On pourrait être tenté de regrouper toute cette matière dans un seul fichier. Plusieurs raisons s'y opposent, et la mécanique posée à la section précédente en éclaire les principales :
- La pondération par le retrieval. Comme on l'a vu, le système opère le retrieval au niveau du passage, pas du document. Des documents courts et focalisés produisent des embeddings précis, là où un fichier long et hétérogène dilue chaque sujet dans un score moyen. Découper, c'est aider le système à retrouver ce qui compte au bon moment.
- La maintenance. Chaque document évolue à un rythme propre. Le glossaire s'enrichit régulièrement, le system prompt change rarement. Les séparer permet de mettre à jour ce qui bouge sans toucher au reste.
- La gouvernance. Différentes personnes peuvent maintenir différents documents — c'est particulièrement utile sur les knowledge bases d'équipe.
- La portabilité. Quand on transfère la knowledge base d'un outil à l'autre, des fichiers découpés s'adaptent plus facilement aux limites de chaque plateforme.
3.3 Une logique de système, pas une checklist
Ces neuf documents ne se lisent pas indépendamment. Ils se croisent en permanence : le system prompt référence les autres, le scope croise le contexte, les exemples valides s'appuient sur les templates, les décisions validées renvoient au scope. C'est cette circulation qui transforme un dossier de fichiers en référentiel cohérent.
Et c'est aussi ce qui rend l'ensemble robuste à l'usage. Quand le modèle traite une nouvelle demande, il n'active pas tous les documents — il retrouve les passages pertinents à travers eux. Si la structure est bien posée, la couche correcte est mobilisée au bon moment : le system prompt pour le cadre, l'identité pour le ton, les templates pour le format, les décisions validées pour la cohérence dans le temps. C'est ce mécanisme qui produit la sensation d'un assistant qui "sait". Il ne sait pas, il récupère, mais le résultat est indistinguable.
4. Les principes de formatage qui rendent une knowledge base exploitable
La structure documentaire qu'on vient de poser ne suffit pas. Encore faut-il que chaque document soit rédigé d'une manière qui maximise sa lisibilité par le système de retrieval. Cinq principes, tous justifiés par la mécanique de la section 2, structurent cette pratique.
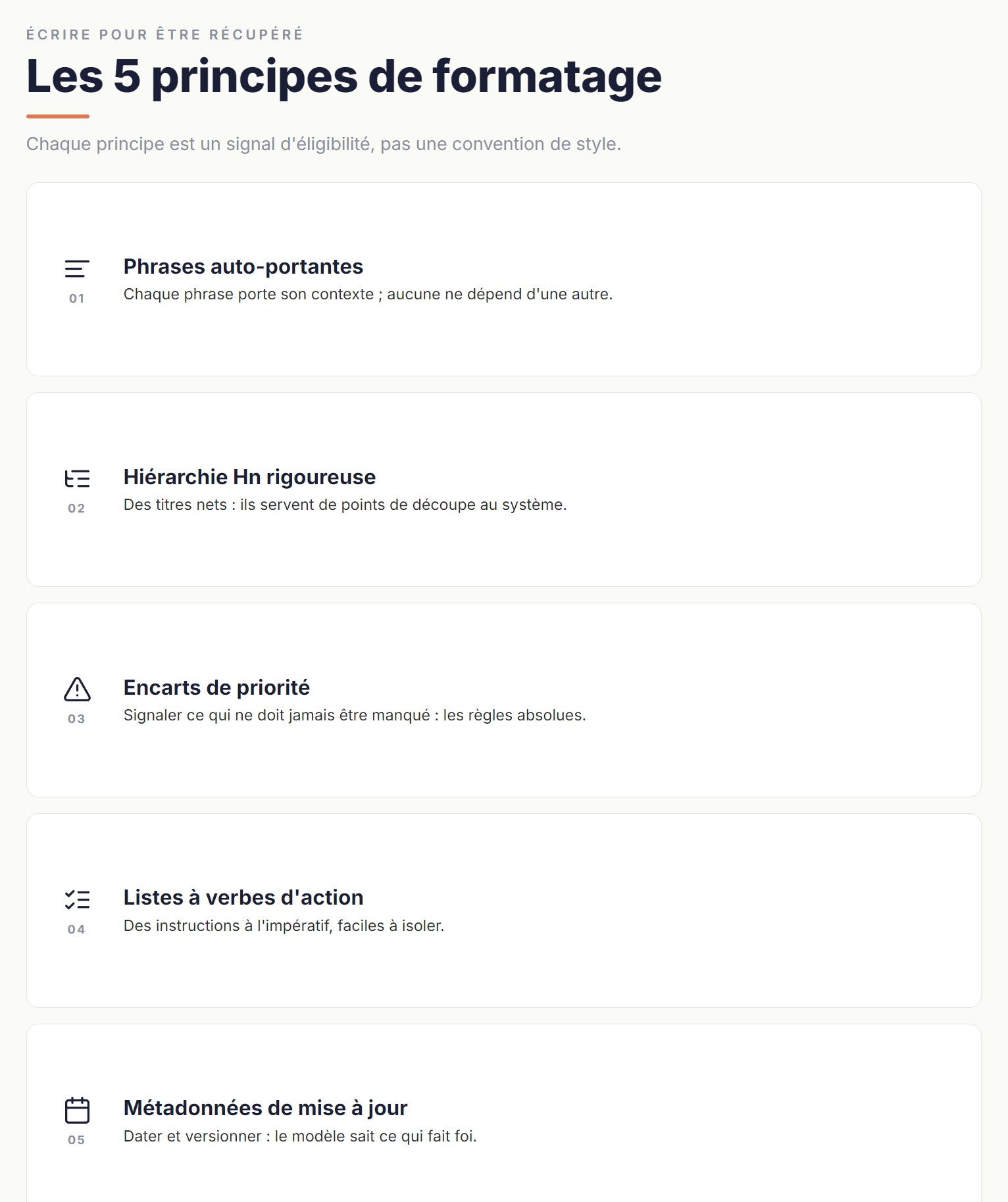
4.1 Phrases auto-portantes
Chaque paragraphe doit pouvoir être extrait isolément et garder son sens. Concrètement : éviter les "comme vu plus haut", "tel que mentionné précédemment", "pour les raisons évoquées ci-dessus". Reformuler les références plutôt que de les sous-entendre. Assumer une légère redondance pour préserver l'autosuffisance des fragments.
Cette règle découle directement du fait que le retrieval opère au niveau du passage. Un passage qui dépend d'un contexte chargé ailleurs sera systématiquement moins retrouvé, et quand il sera retrouvé, son sens sera dégradé.
4.2 Hiérarchie Hn rigoureuse
Le modèle utilise les niveaux de titres pour comprendre l'architecture d'un document et pour pondérer l'importance des passages. Une hiérarchie cohérente — H1 pour le sujet du document, H2 pour les grandes sections, H3 pour les sous-sections, sans saut de niveau — permet au système d'identifier rapidement où chercher quoi.
À l'inverse, un document plat ou désordonné force le système à deviner. Il devine bien — mais moins bien que quand vous le lui dites explicitement.
4.3 Encarts de priorité explicites
Les LLM détectent et pondèrent les marqueurs de priorité explicites. "RÈGLE CRITIQUE :", "À LIRE EN PRIORITÉ :", "NE JAMAIS :" donnent du poids à ce qui suit. Les sections sans marqueur sont lues sur un même plan.
C'est un levier largement sous-utilisé. Un system prompt qui distingue clairement les comportements obligatoires des comportements préférés est respecté avec une fiabilité supérieure à un system prompt qui pose tout sur un seul ton.
4.4 Listes structurées avec verbes d'action
Pour les règles comportementales, les listes avec verbes d'action en tête sont plus efficaces que les paragraphes descriptifs :
- "Privilégier les formulations positives"
- "Citer toujours la source"
- "Refuser de produire X"
Ce format est plus lisible pour l'humain qui maintient le document, et plus directement actionnable pour le modèle qui s'en sert de référence. Une règle formulée à l'infinitif avec un verbe d'action est moins ambiguë qu'une phrase déclarative.
4.5 Métadonnées de mise à jour
Chaque document de la knowledge base intègre, en en-tête, ses repères de gouvernance :
- la date de dernière mise à jour
- le numéro de version
- la nature de la dernière modification
Sans ces métadonnées, on ne sait jamais ce qui est encore valide et ce qui ne l'est plus. Et le modèle non plus.
5. Quatre principes éprouvés à l'usage
Au-delà du formatage, quatre principes d'écriture font la différence entre une knowledge base qui fonctionne et une qui ne fonctionne pas. Ils tiennent moins à la forme qu'à la stratégie de rédaction.
Écrire pour le modèle, pas pour l'humain
Une knowledge base n'est pas une fiche de présentation. Elle peut être dense, technique, parfois redondante. Elle n'est pas faite pour être lue, mais pour être consultée par un LLM qui en extraira ce dont il a besoin au moment où il en a besoin. La précision opérationnelle prime sur la qualité rédactionnelle.
Cette inversion de perspective change beaucoup. Vous n'avez pas à éviter une formulation parce qu'elle se répète. Vous n'avez pas à introduire avec style chaque section. Vous n'avez pas à soigner les transitions. Ce que vous devez soigner, c'est l'autosuffisance de chaque passage et la précision de chaque règle.
Donner des exemples et des contre-exemples
"Voici un paragraphe qu'on validerait" / "Voici un paragraphe qu'on ne validerait pas, et pourquoi". Ce format apporte une efficacité que la règle abstraite ne produit pas. Le modèle traite plus efficacement le contraste qu'une définition seule. Sur le tone of voice en particulier, les contre-exemples sont précieux — ils précisent ce qu'aucune règle générale ne peut formuler aussi clairement.
C'est aussi le format qui tient le mieux sur la durée. Une règle se discute, un exemple s'ajuste. Une bibliothèque d'exemples validés est l'actif qui rend une knowledge base réellement opérationnelle dans la durée.
Documenter le négatif
Ce qu'on ne veut pas est souvent plus discriminant que ce qu'on veut. "Ne jamais utiliser le mot disruption." "Ne jamais conclure par une question rhétorique." "Ne jamais proposer de fonctionnalité qui n'existe pas dans le produit." Ces interdictions explicites éliminent en un coup les patterns par défaut du modèle qui ne correspondent pas à votre contexte.
C'est particulièrement vrai sur les comportements génératifs profondément ancrés dans l'entraînement du modèle : tournures évangéliques, conclusions creuses, transitions banales, recours systématique aux listes à puces. Sans interdiction explicite, ils ressortent par défaut.
Itérer après les premiers usages réels
La première version d'une knowledge base est toujours imparfaite. Ce sont les premières conversations qui font émerger les manques : un cas non couvert, une règle qu'on croyait évidente et qui ne l'est pas, une formulation qui produit des effets de bord inattendus.
Plutôt que de chercher la version parfaite avant de commencer, posez une v1 raisonnable et enrichissez-la au fil des sessions. La meilleure knowledge base n'est pas celle qui a été conçue le mieux. C'est celle qui a vécu.
6. La vigilance documentaire qui protège l'actif
Une knowledge base bien construite évolue dans le temps. Mais cette évolution a une condition : la qualité de placement et de maintenance. Deux dimensions méritent qui une attention particulière.
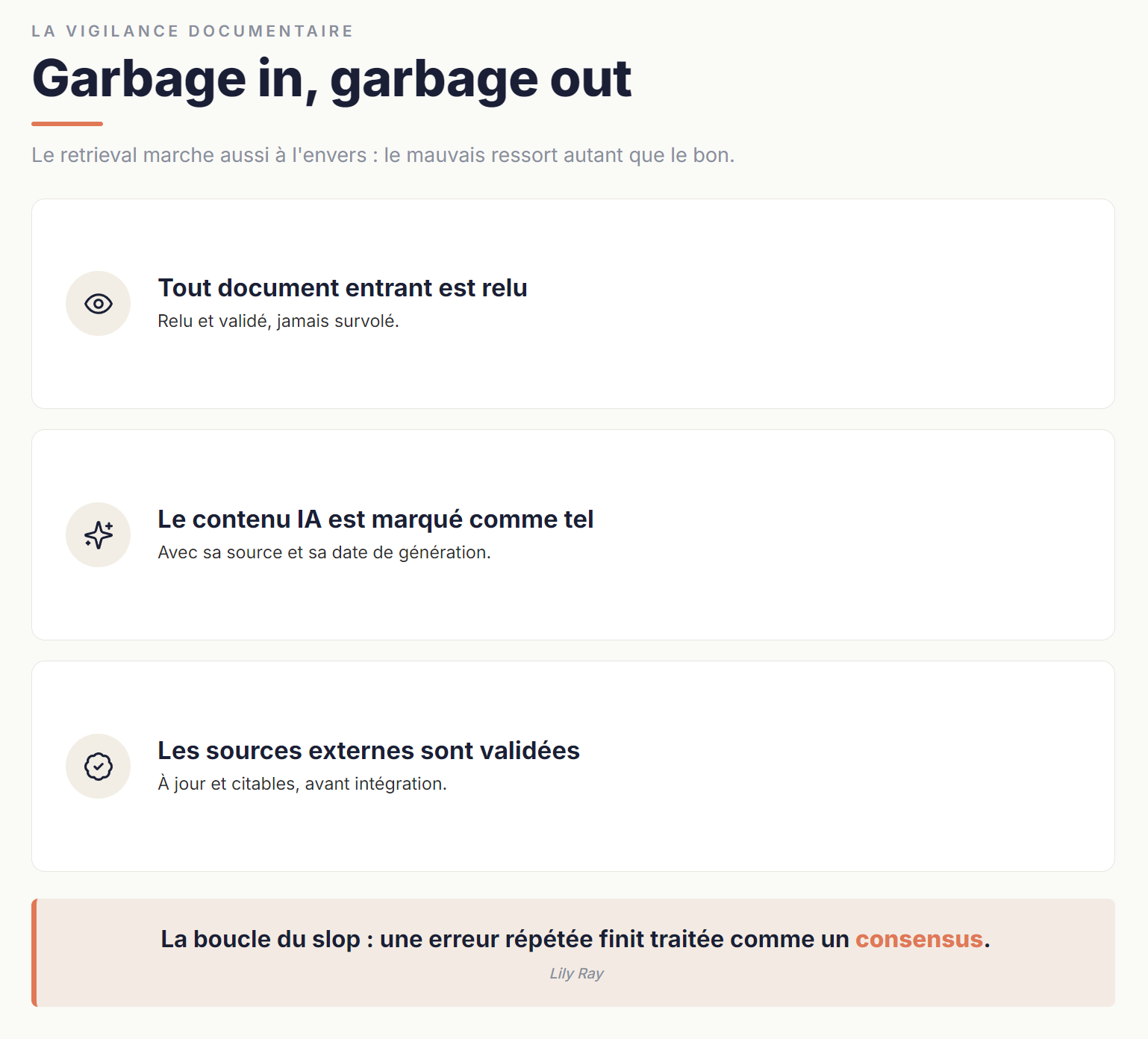
6.1 Garbage in, garbage out
Le mécanisme de récupération qui rend votre knowledge base utile fonctionne aussi en sens inverse : ce qui y est mauvais ressort autant que ce qui y est bon. C'est une évidence quand on le dit mais c'est beaucoup moins évident dans la pratique quotidienne — où la tentation est grande d'enrichir la knowledge base à coups de copier-coller, d'extraits web non vérifiés, de notes générées par IA sans relecture.
Lily Ray a documenté le mécanisme à l'échelle du web dans son article The AI Slop Loop : du contenu généré par IA hallucine un détail, des sites le republient, le système de retrieval traite la répétition comme un consensus, et l'erreur s'installe. À l'échelle de votre knowledge base, le risque est plus localisé mais opère par la même mécanique : ce que vous y placez sera traité comme la vérité du projet. Une note mal sourcée, une formulation IA non relue, une donnée qui aurait dû être actualisée — chacune devient un passage indexé, candidat au retrieval, mobilisable au moment où vous attendez de la précision.
Trois règles d'hygiène simples suffisent à éviter le problème :
- Tout document entrant dans la knowledge base est relu. Pas survolé, relu et validé.
- Le contenu généré par IA est marqué comme tel quand il est conservé, idéalement avec la mention de la source et de la date de génération. Cela permet de le réévaluer plus facilement à la révision.
- Les sources externes sont validées avant intégration. Si vous indexez la documentation d'un outil, vérifiez qu'elle est à jour. Si vous indexez une étude, vérifiez qu'elle est citable.
Ce n'est pas du formalisme. C'est la condition pour que la knowledge base reste l'actif différencié décrit en section 1 — et non un dépôt qui dérive lentement vers ses propres erreurs.
6.2 La maintenance comme hygiène
Une knowledge base bien tenue est une knowledge base qui évolue. Trois rythmes de maintenance fonctionnent bien en pratique :
- À la fin d'une session de travail, si une règle ou un apprentissage a émergé qui mérite d'être consigné.
- Après chaque validation explicite d'une formulation, d'une décision, d'un choix éditorial — pour que la prochaine session en bénéficie sans avoir à le redémontrer.
- En revue hebdomadaire ou mensuelle, pour identifier les sections qui ont ont perdu leur contexte, les contradictions qui se sont installées entre plusieurs documents, les manques qui sont apparus.
Cette maintenance peut se faire avec l'aide du modèle lui-même. Sur demande, Claude peut produire un résumé des règles qui ont émergé d'une session, en pointant lesquelles méritent d'être ajoutées à la knowledge base et où. C'est un gain de temps important, à condition de relire ce qu'il propose avant intégration — voir la règle d'hygiène précédente.
Un point pratique à connaître sur Projects Claude : les fichiers de la knowledge base sont en lecture seule. Toute modification implique de modifier le fichier en local, puis de réimporter la version mise à jour. Ce n'est pas un défaut, c'est une protection — qui évite que la knowledge base dérive sans qu'on s'en rende compte. Mais cela impose une discipline : utiliser un système de fichiers local versionné (Obsidian, Notion, ou simplement un dossier Git) comme source de vérité, et synchroniser régulièrement vers le Project.
7. Quelques cas d'usage
La méthode présentée ici se transpose à tous les usages récurrents d'un LLM. Selon votre activité, plusieurs configurations méritent d'être citées :
- Knowledge base éditoriale — pour une production de contenu régulière : ligne éditoriale, tone of voice, sources de référence, sujets déjà traités. Le blog que vous lisez en ce moment fonctionne sur ce modèle.
- Knowledge base métier — pour vos propres références d'expert : méthodes, frameworks, sources de fond, formulations, positionnements sur des sujets clivants. Probablement la configuration qui a le plus d'impact opérationnel pour un professionnel, parce qu'elle permet au LLM de travailler dans le prolongement de votre propre méthode.
- Knowledge base d'équipe — pour un service, un département, une organisation : processus, standards de qualité, références internes, bonnes pratiques. Particulièrement adaptée aux Projects partagés (Claude Team, ChatGPT Business).
- Knowledge base produit ou marque — pour un produit, un SaaS, une marque en propre : positionnement, messages clés, FAQ, objections, cas d'usage. Aligne les équipes marketing, sales et support sur une base unique.
- Knowledge base client — pour les consultants, agences, freelances qui interviennent sur plusieurs comptes : une knowledge base par client capitalise la connaissance accumulée mission après mission.
- Knowledge base de domaine — pour faire monter en compétence un LLM sur un secteur précis (juridique, médical, technique, financier). Elle transforme un modèle généraliste en assistant sectoriel.
Le principe est le même dans tous les cas : une structuration claire, une rédaction lisible par la machine, une maintenance disciplinée. Ce qui change, c'est le contenu des neuf documents — pas leur logique.
8. Et après : construire la knowledge base en amont
Tout ce qui précède décrit la knowledge base telle qu'elle existe dans votre Projet, une fois posée. Il reste une question importante : où la rédigez-vous ?
Ce n'est pas un détail. Une knowledge base bien construite vit, s'enrichit, se restructure. La rédiger directement dans l'interface du Projet est possible au début, mais ne tient pas dans la durée — d'abord parce que les fichiers y sont en lecture seule, ensuite parce qu'on n'y a aucun versionning, aucune recherche transverse, aucune capacité de réorganisation rapide. La knowledge base efficace suppose un outil de construction en amont : un système de fichiers local où vous tenez vos documents, les éditez, les reliez entre eux, en gardez l'historique, et que vous synchronisez vers le Project quand une nouvelle version est prête.
C'est dans ce rôle d'outil amont qu'Obsidian a pris une place particulière dans ma pratique. Un éditeur Markdown natif, un système de fichiers local versionnable avec Git, une recherche full-text rapide, des liens entre documents, et un écosystème de plugins qui permet de l'adapter à des besoins très spécifiques — le triplé qui rend la construction et la maintenance d'une knowledge base réellement fluide. Je consacrerai à Obsidian un article dédié dans la suite, où on regardera de plus près comment il s'intègre concrètement dans un workflow d'expert SEO, LLM, ou plus largement de travailleur de la connaissance.
D'ici là, l'essentiel de cet article tient en une idée : votre knowledge base n'est pas un dossier de fichiers, c'est un système de récupération ancrée que vous configurez à la main. Sa qualité dépend de la rigueur que vous mettez à le penser comme tel — dans sa structure, dans son écriture, dans sa maintenance. C'est cette rigueur qui transforme un outil générique en collaborateur calibré, qui sait où vous en êtes, qui parle votre langage, et qui capitalise sur ce que vous lui apprenez session après session.
Si vous pratiquez déjà la knowledge base, vos propres adaptations m'intéressent. C'est le genre de méthode qui se renforce par les usages réels.
Sources et lectures complémentaires
Documentation officielle
- Anthropic — Projects
- Anthropic — RAG for Projects
- OpenAI — Projects in ChatGPT
- OpenAI — Knowledge in GPTs
Veille experte mobilisée
- Pedro Dias / The Inference — Your AI Strategy Isn't a Strategy — It's SEO With a Rebrand
- Pedro Dias / The Inference — Publishing Everything Is a Terrible Business Strategy
- Mike King / iPullRank — How AI Mode Works
- Mike King / iPullRank — Moving from a Google-shaped Web to an Agent-shaped Web: A Refutation of Misinformation about Chunking
- Lily Ray — The AI Slop Loop